import pandas as pd
mpg = pd.read_csv('mpg.csv')Do it! 쉽게 배우는 파이썬 데이터 분석
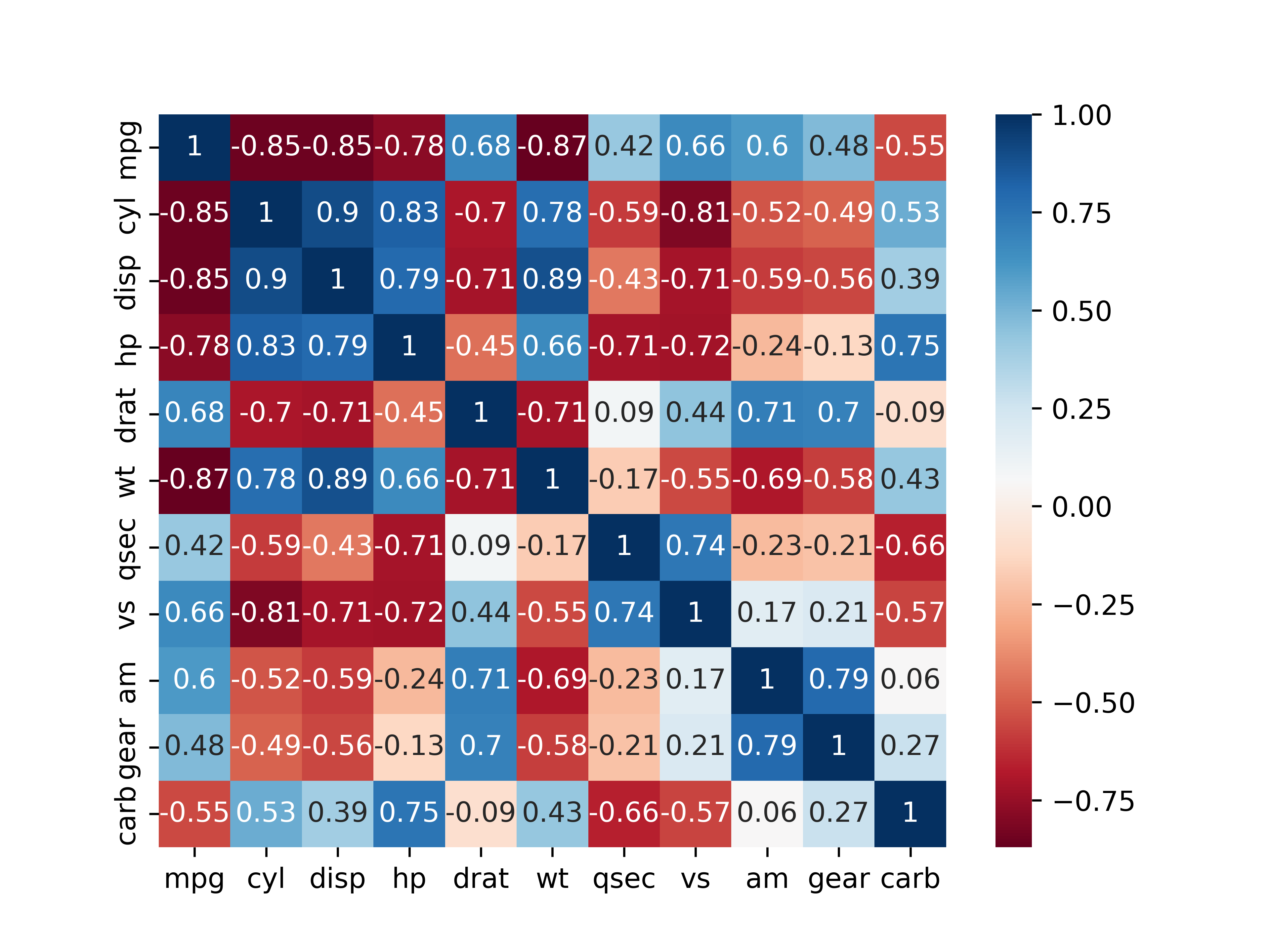
- 상관계수가 클수록 상자 색깔을 진하게 표현
- 상관계수가 양수면 파란색, 음수면 빨간색 계열로 표현
- 상자 색깔을 보면 상관관계의 정도와 방향을 쉽게 파악할 수 있음
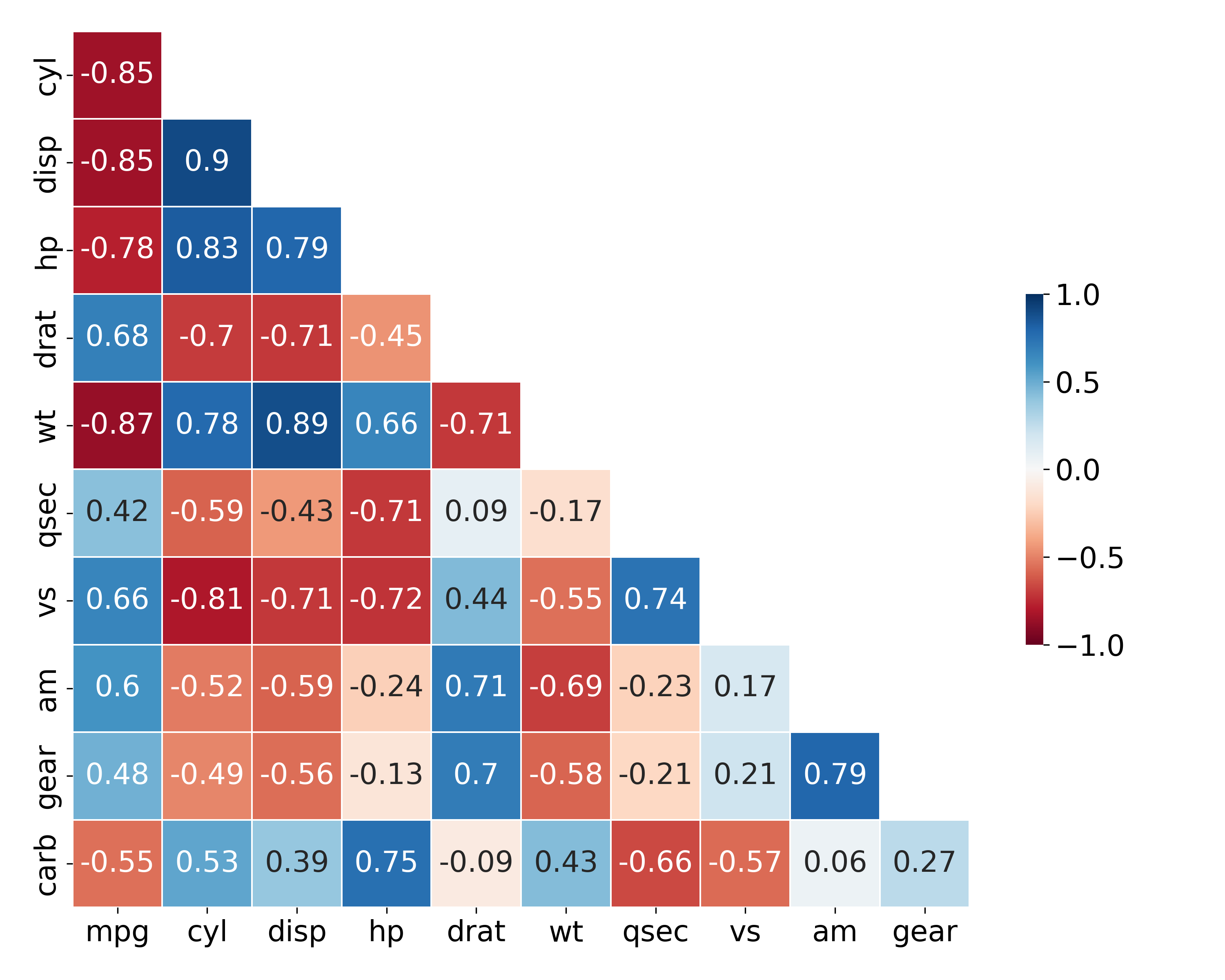
(2) 히트맵에 mask 적용하기
sns.heatmap()에mask적용mask의 1에 해당하는 위치의 값이 제거되어 왼쪽 아래의 상관계수만 표현됨
# 히트맵 만들기
sns.heatmap(data = car_cor,
annot = True, # 상관계수 표시
cmap = 'RdBu', # 컬러맵
mask = mask) # mask 적용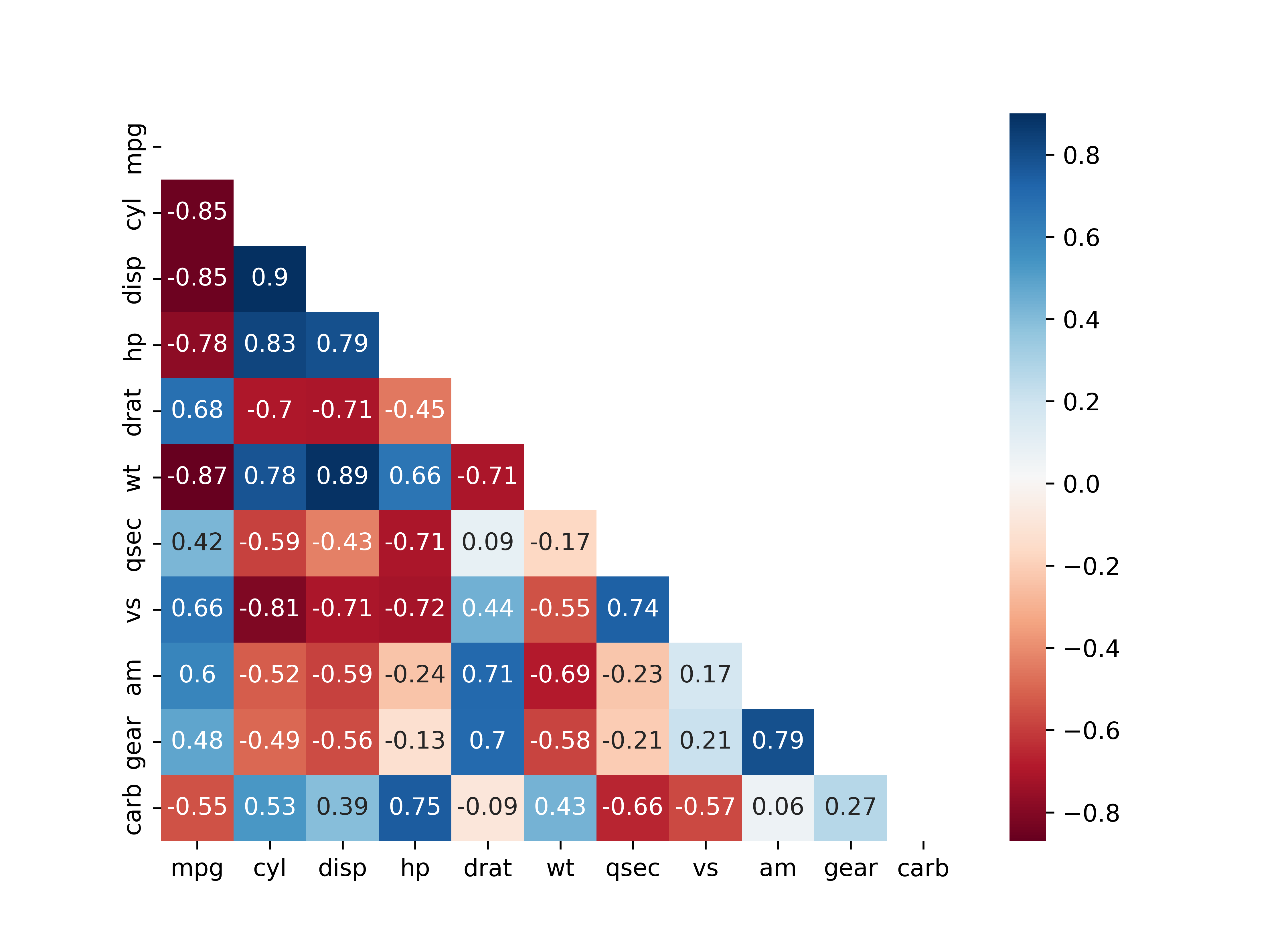
(3) 빈 행과 열 제거하기
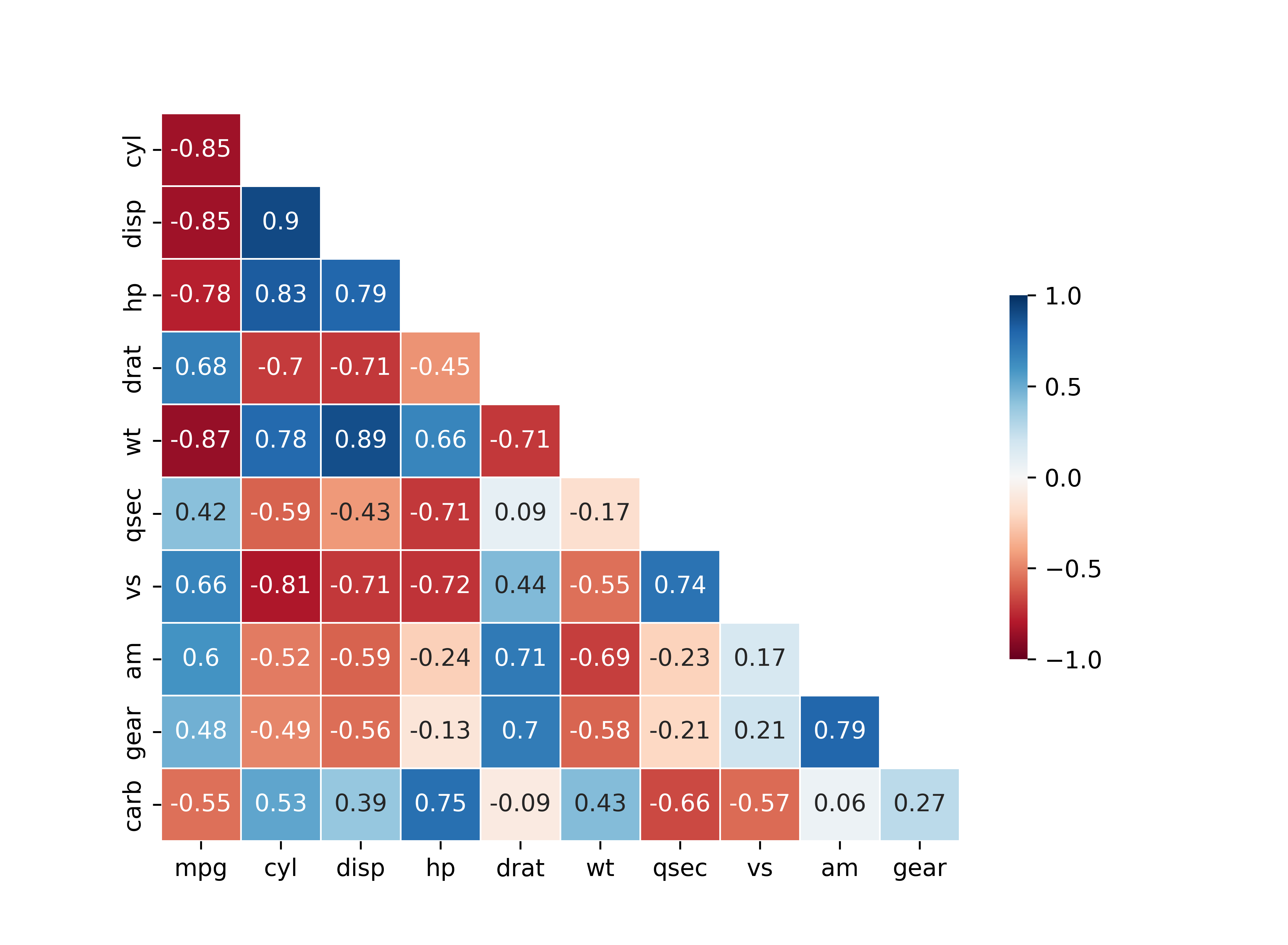
- 앞에서 만든 히트맵의 왼쪽 위
mpg행, 오른쪽 아래carb열에 아무 값도 표현되어 있지 않음 - 행과 열의 변수가 같아서 상관계수가 항상 1이 되는 위치이므로 값을 표현하지 않은 것
mask와 상관행렬의 첫 번째 행과 마지막 열을 제거해서 빈 행과 열 제거
mask_new = mask[1:, :-1] # mask 첫 번째 행, 마지막 열 제거
cor_new = car_cor.iloc[1:, :-1] # 상관행렬 첫 번째 행, 마지막 열 제거
sns.heatmap(data = cor_new,
annot = True, # 상관계수 표시
cmap = 'RdBu', # 컬러맵
mask = mask_new) # mask 적용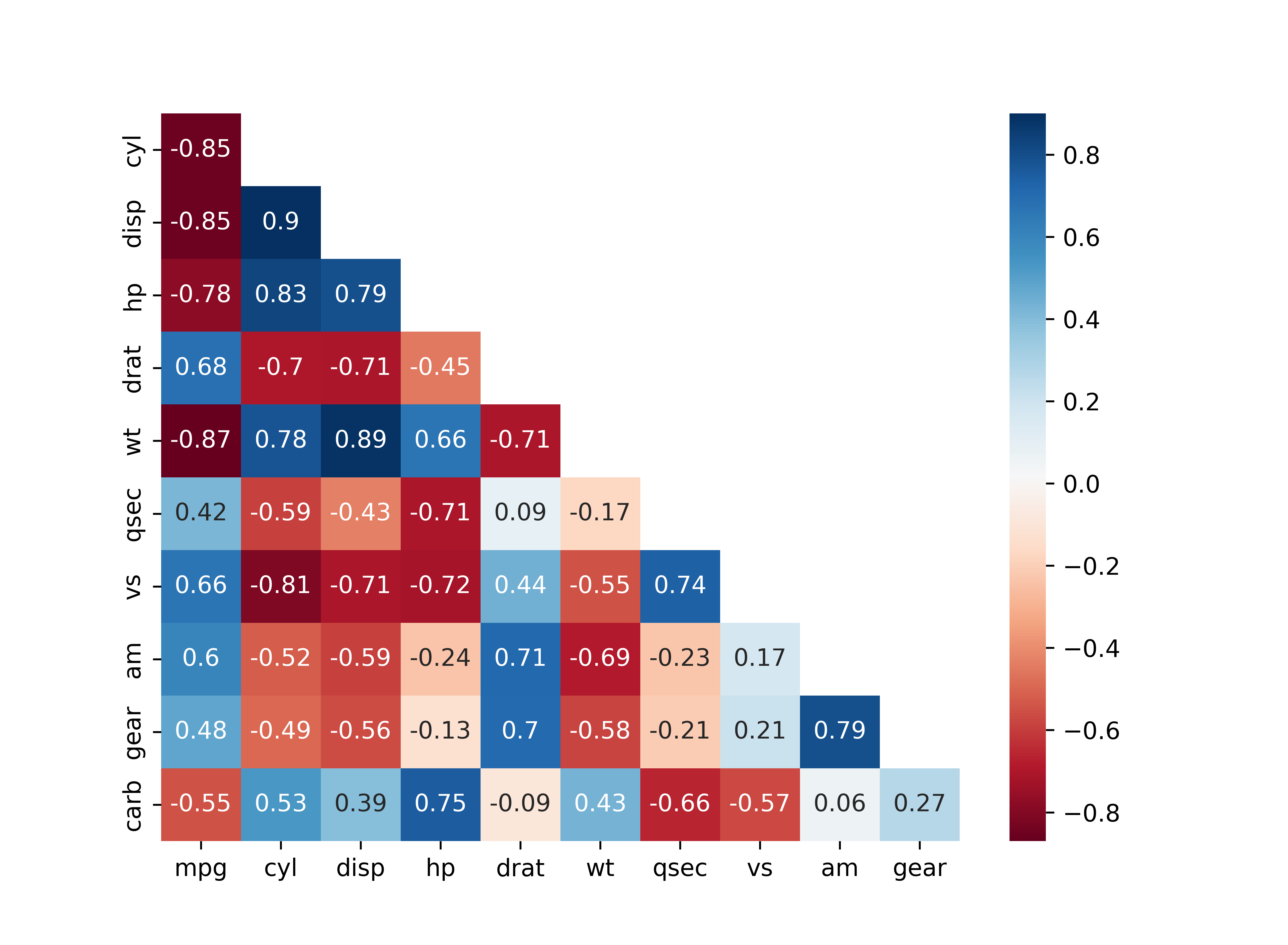
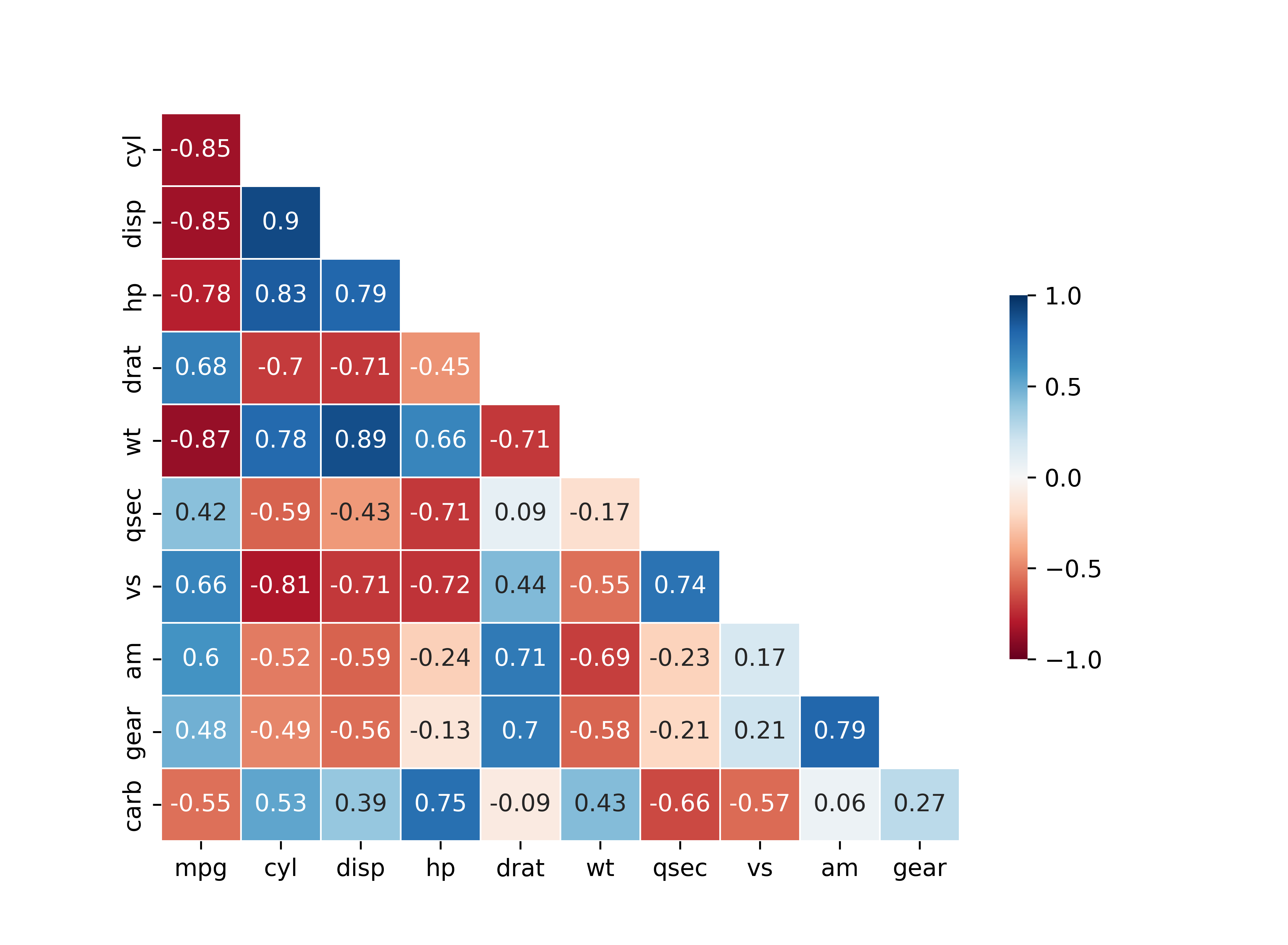
보기 좋게 수정하기
sns.heatmap(data = cor_new,
annot = True, # 상관계수 표시
cmap = 'RdBu', # 컬러맵
mask = mask_new, # mask 적용
linewidths = .5, # 경계 구분선 추가
vmax = 1, # 가장 진한 파란색으로 표현할 최대값
vmin = -1, # 가장 진한 빨간색으로 표현할 최소값
cbar_kws = {'shrink': .5}) # 범례 크기 줄이기