Do it! 쉽게 배우는 파이썬 데이터 분석
산점도 만들기
import pandas as pd
mpg = pd.read_csv('mpg.csv')# x축은 displ, y축은 hwy를 나타낸 산점도 만들기
import seaborn as sns
sns.scatterplot(data = mpg, x = 'displ', y = 'hwy')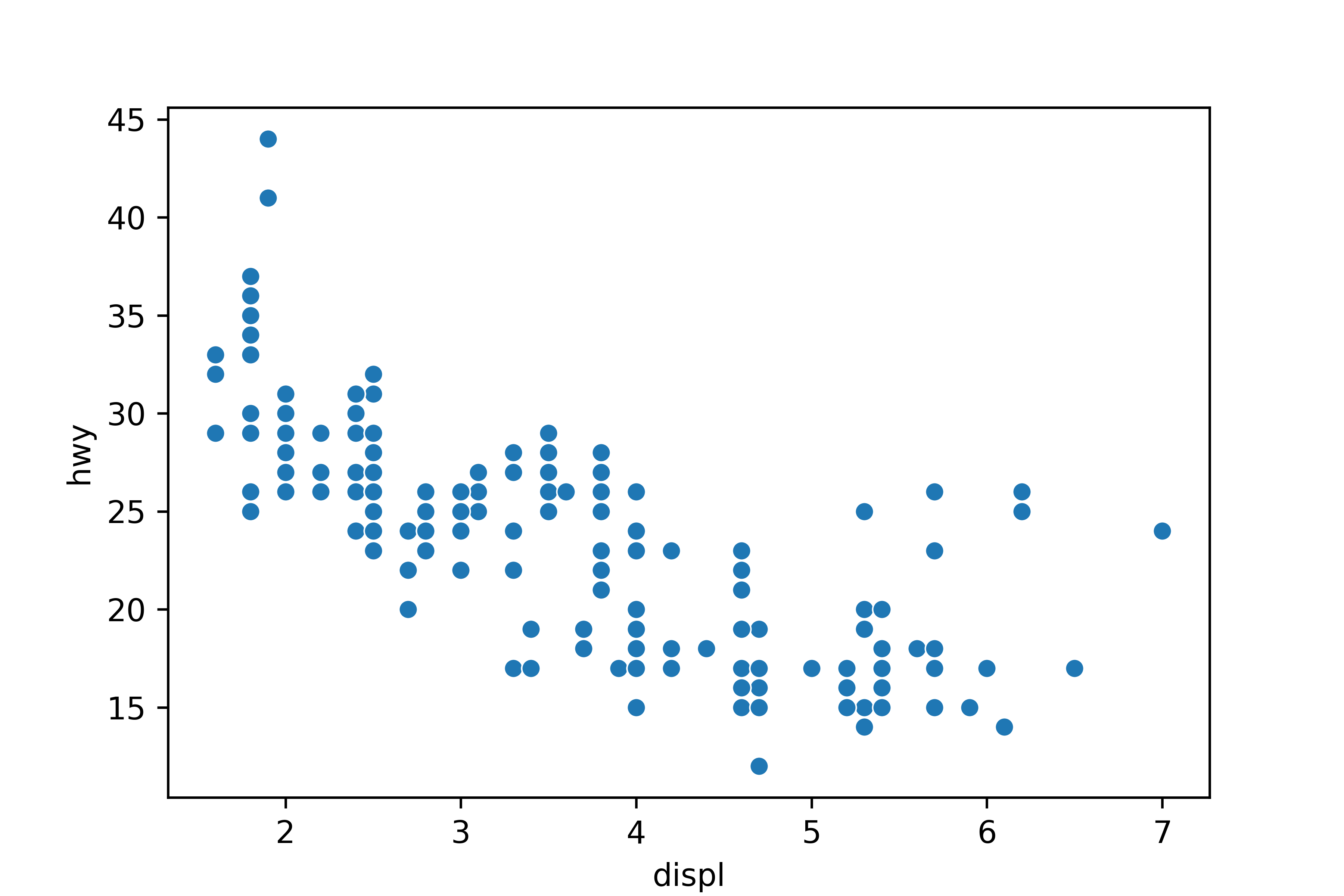
축 범위 설정하기
# x축 범위 3~6으로 제한
sns.scatterplot(data = mpg, x = 'displ', y = 'hwy') \
.set(xlim = [3, 6])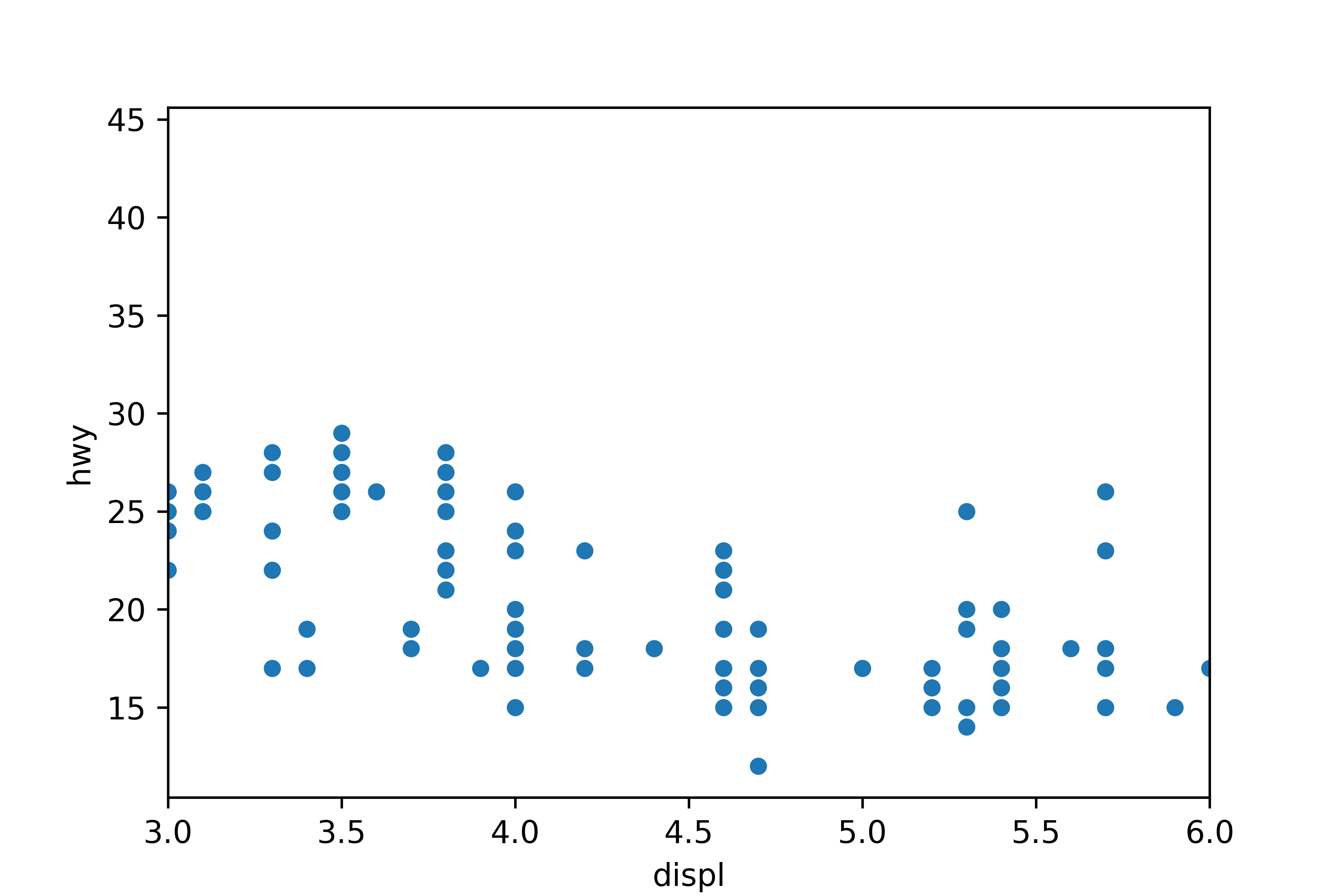
축 범위 설정하기
# x축 범위 3~6, y축 범위 10~30으로 제한
sns.scatterplot(data = mpg, x = 'displ', y = 'hwy') \
.set(xlim = [3, 6], ylim = [10, 30])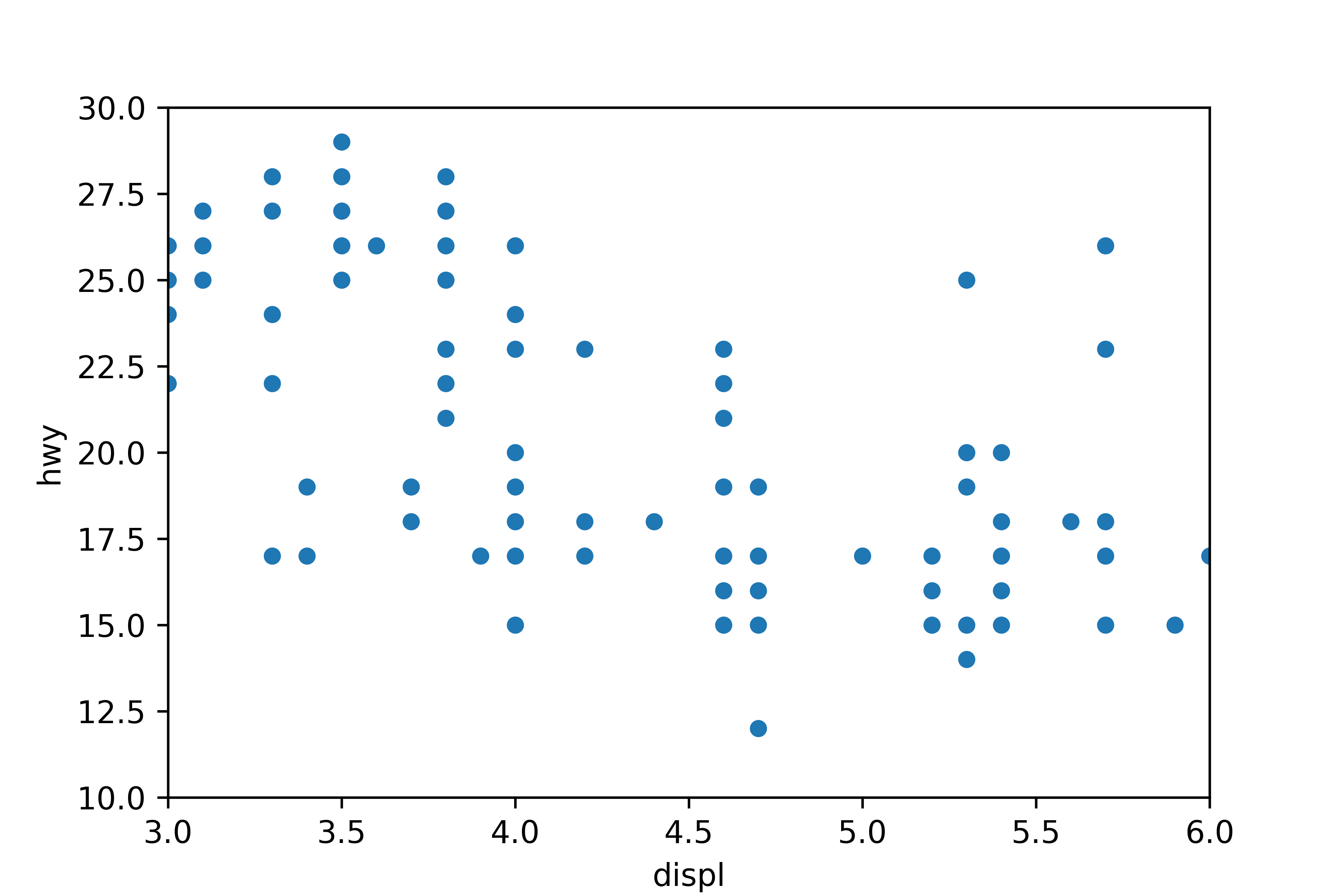
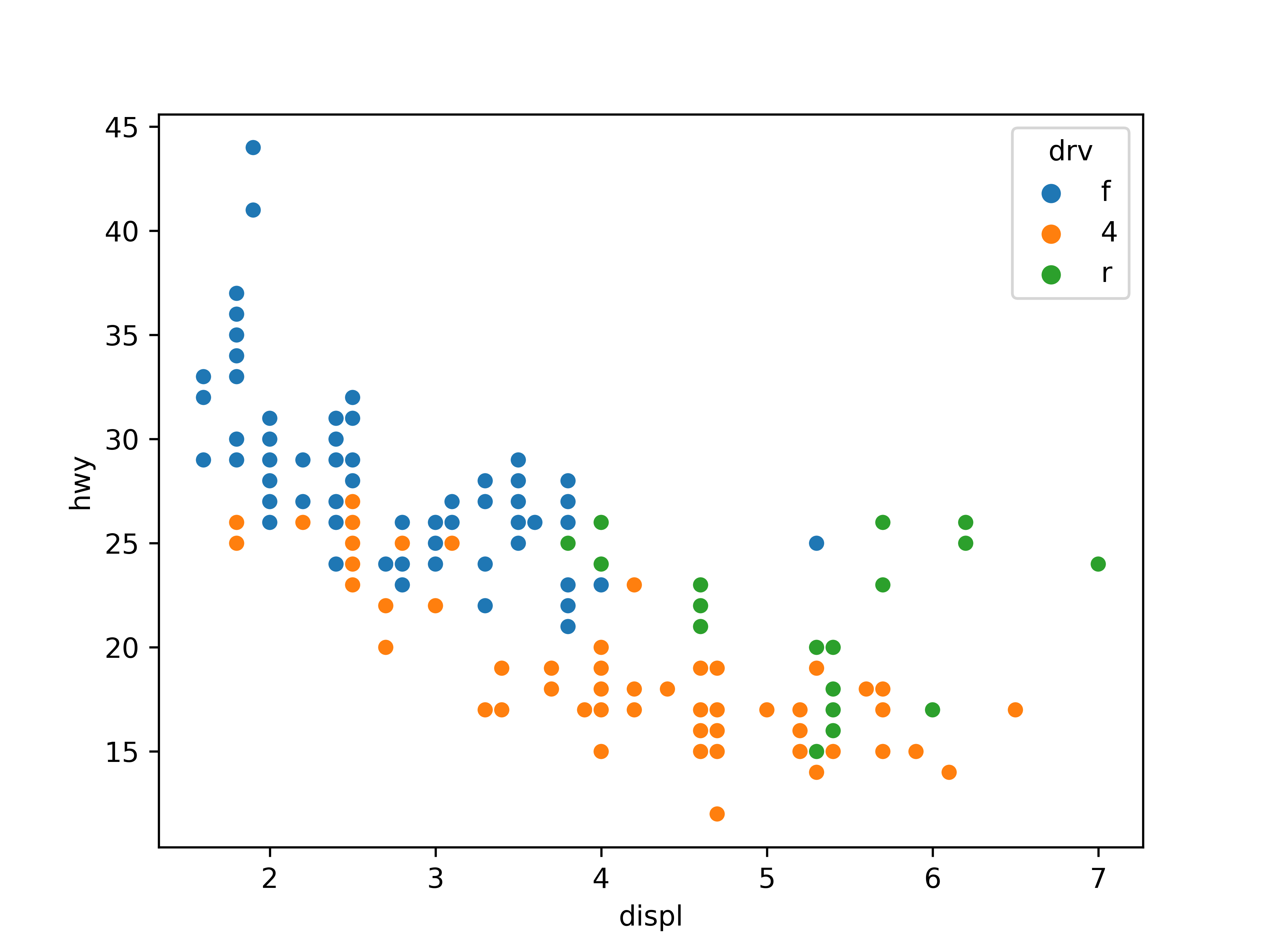
종류별로 표식 색깔 바꾸기
# drv별로 표식 색깔 다르게 표현
sns.scatterplot(data = mpg, x = 'displ', y = 'hwy', hue = 'drv')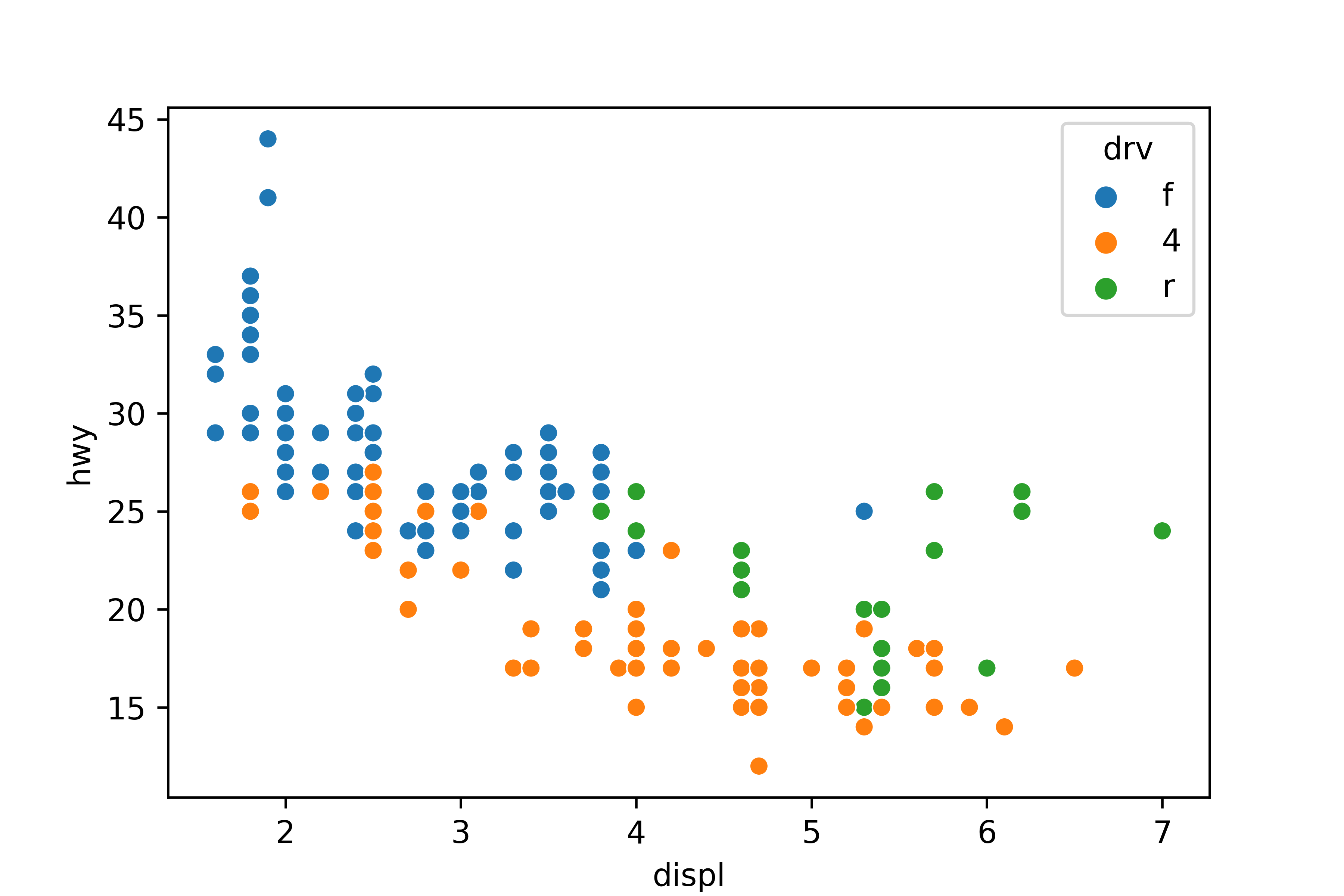
Q1. mpg 데이터의 cty(도시 연비)와 hwy(고속도로 연비) 간에 어떤 관계가 있는지 알아보려고
합니다. x축은 cty, y축은 hwy로 된 산점도를 만들어 보세요.
mpg = pd.read_csv('mpg.csv') # mpg 데이터 불러오기
sns.scatterplot(data = mpg, x = 'cty', y = 'hwy') # 산점도 만들기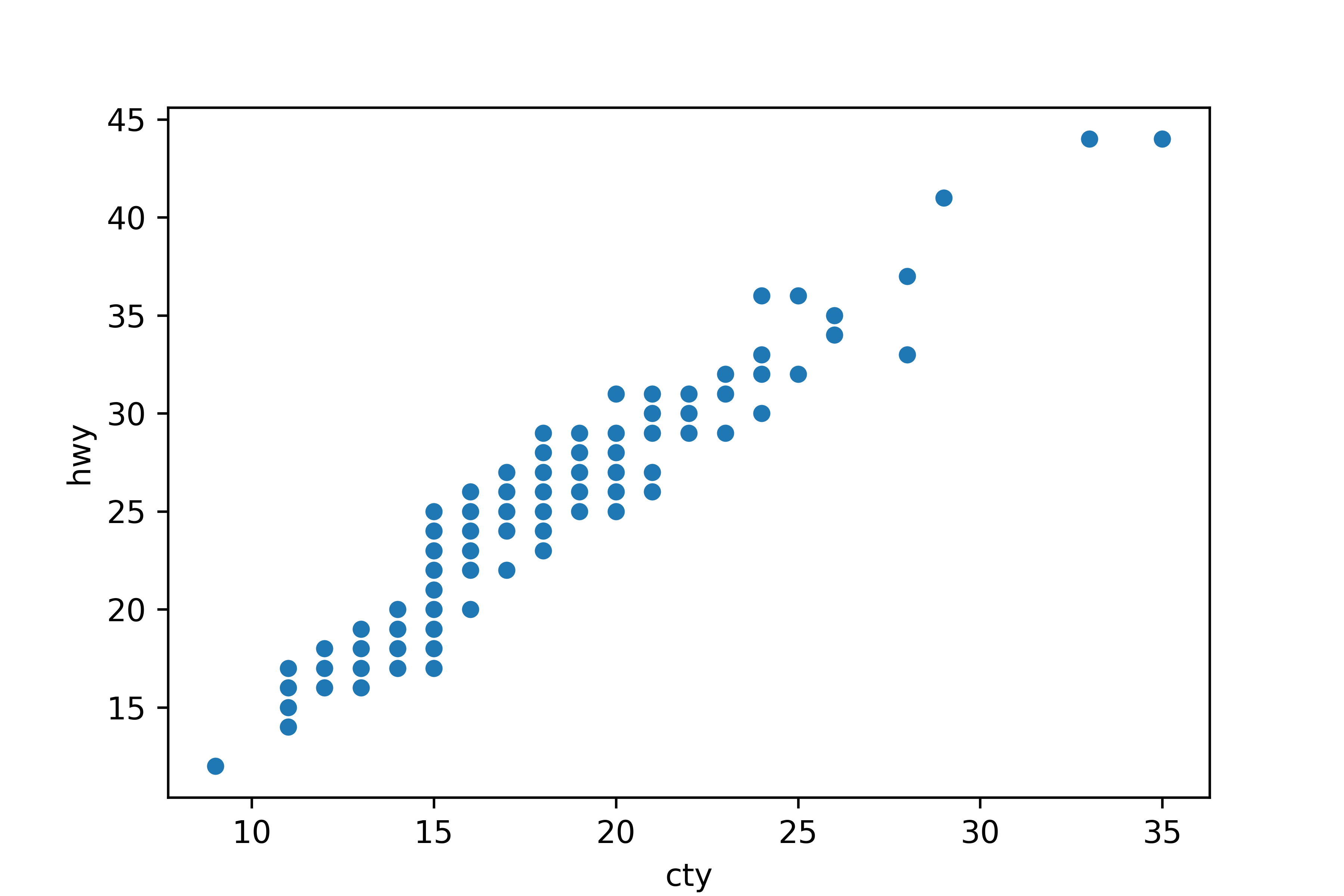
Q2. 미국의 지역별 인구통계 정보를 담은 midwest.csv를 이용해 전체 인구와 아시아인 인구 간에
어떤 관계가 있는지 알아보려고 합니다.
•x축은 poptotal(전체 인구), y축은 popasian(아시아인 인구)으로 된 산점도를 만들어 보세요. •전체 인구는 50만 명 이하, 아시아인 인구는 1만 명 이하인 지역만 산점도에 표시되게 설정하세요.
# midwest 데이터 불러오기
midwest = pd.read_csv('midwest.csv')
# 산점도 만들기, 축 범위 제한하기
sns.scatterplot(data = midwest, x = 'poptotal', y = 'popasian') \
.set(xlim = (0, 500000), ylim = (0, 10000))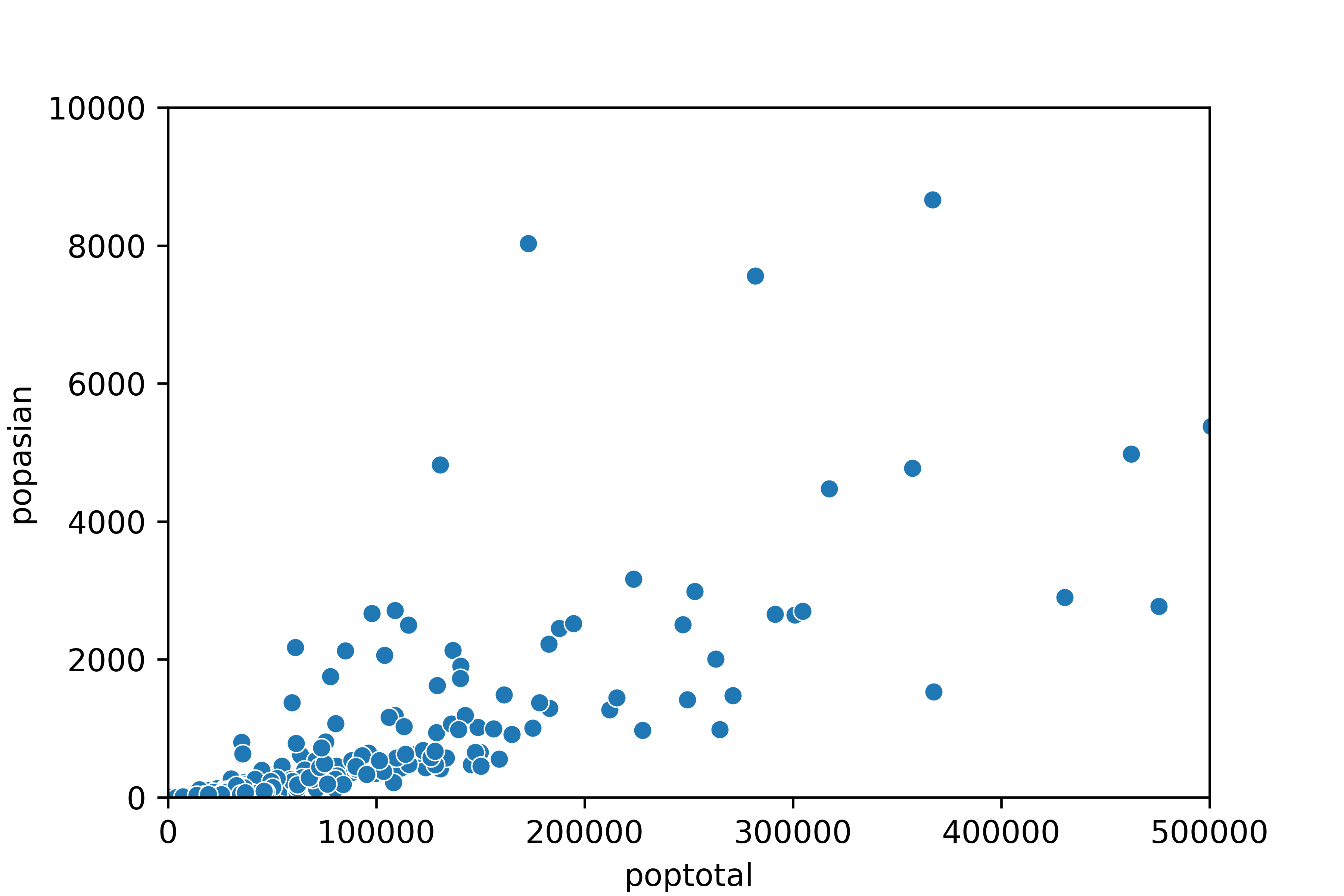
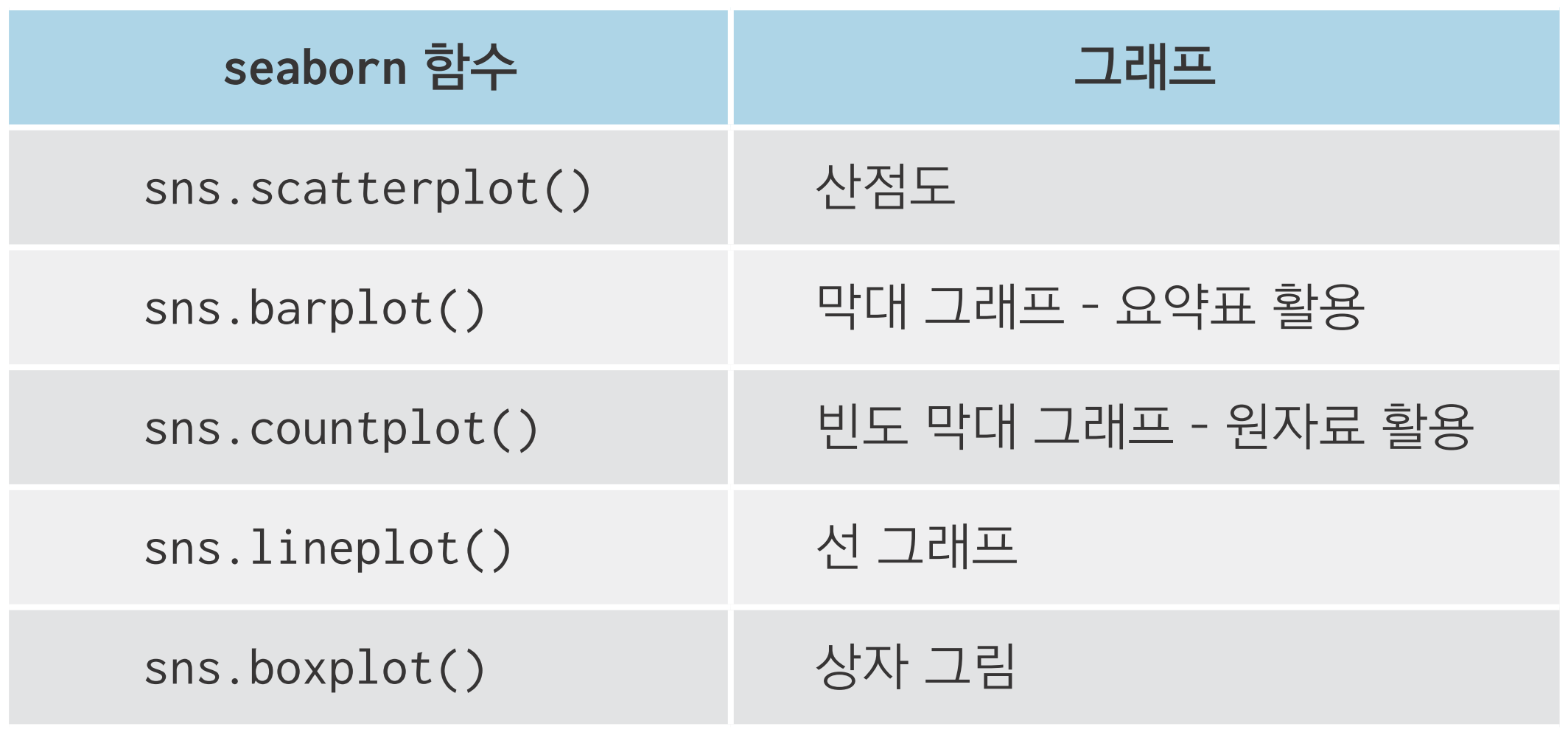
막대 그래프(bar chart)
- 데이터의 크기를 막대의 길이로 표현한 그래프
- 성별 소득 차이처럼 집단 간 차이를 표현할 때 사용
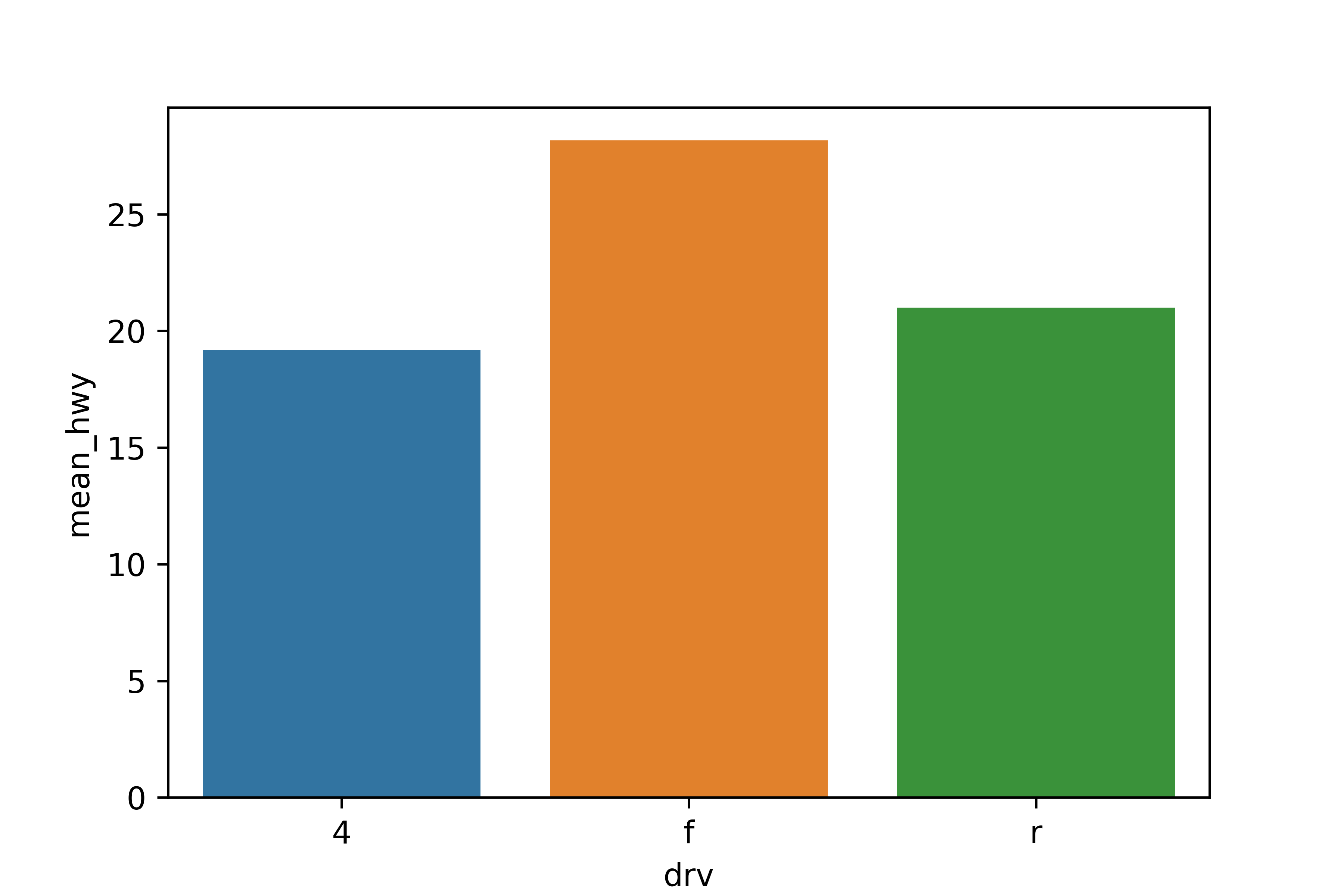
2. 그래프 만들기
sns.barplot(data = df_mpg, x = 'drv', y = 'mean_hwy')
3. 크기순으로 정렬하기
# 데이터 프레임 정렬하기
df_mpg = df_mpg.sort_values('mean_hwy', ascending = False)
# 막대 그래프 만들기
sns.barplot(data = df_mpg, x = 'drv', y = 'mean_hwy')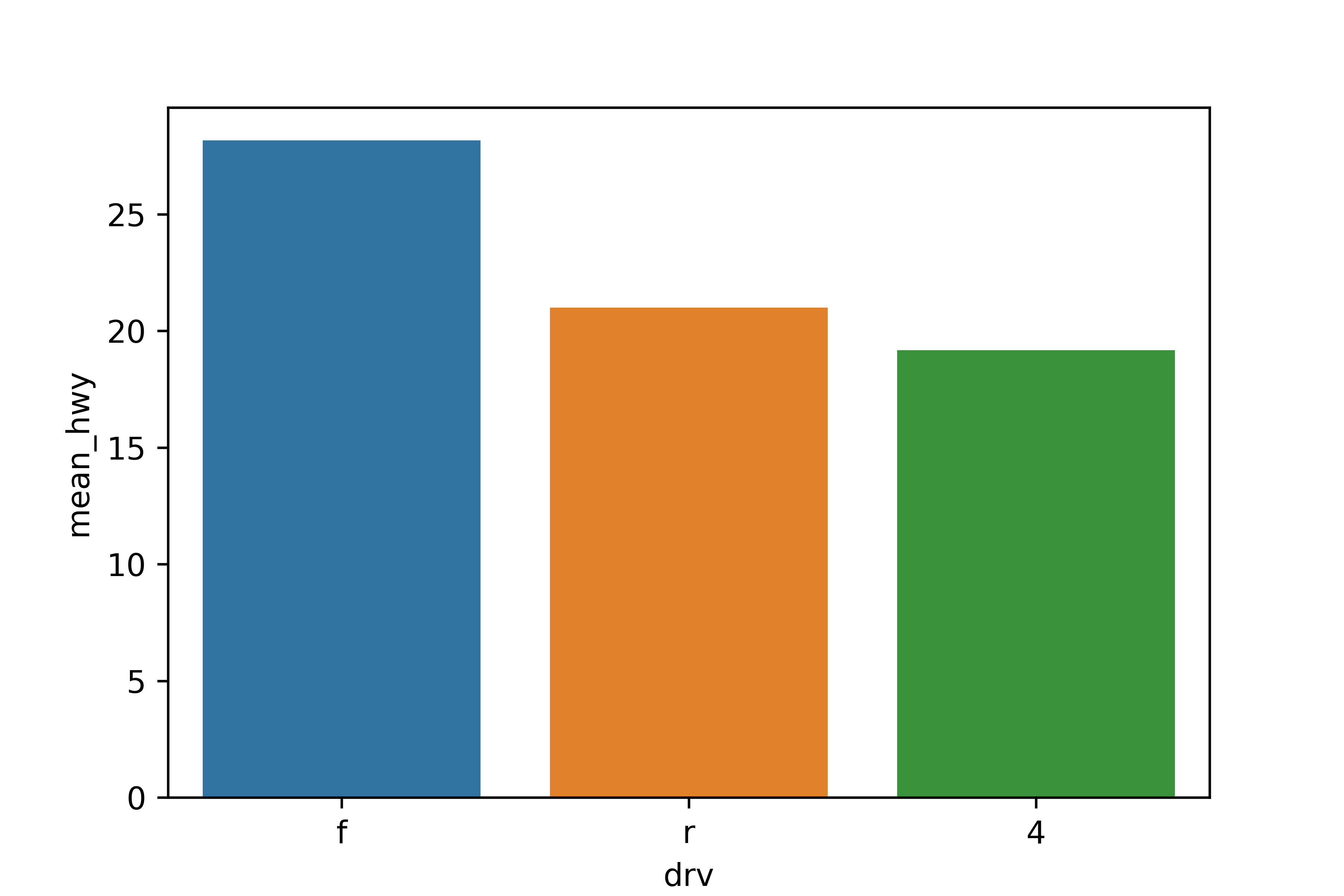
2. 그래프 만들기
# 막대 그래프 만들기
sns.barplot(data = df_mpg, x = 'drv', y = 'n')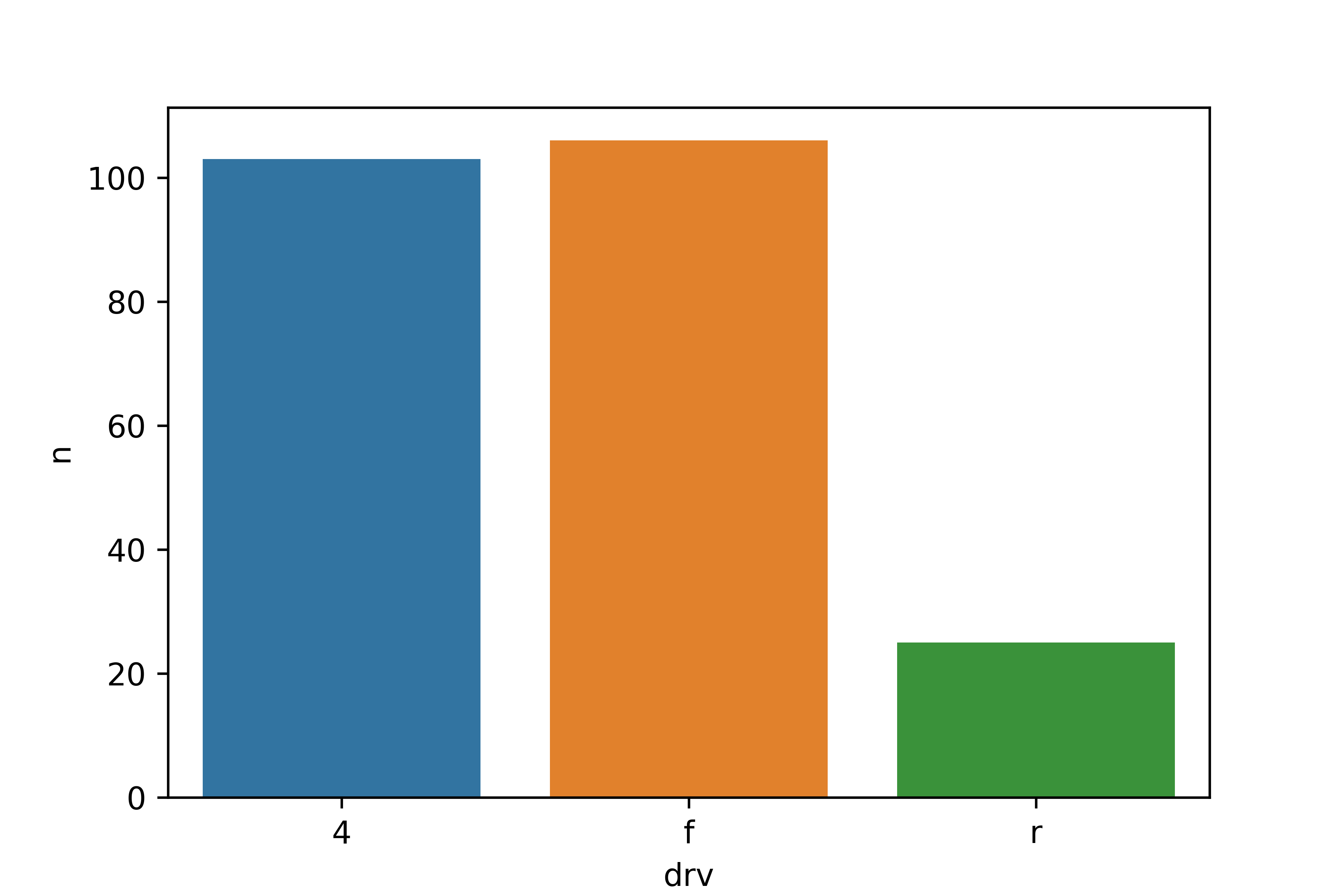
sns.countplot()으로 빈도 막대 그래프 만들기
- 집단별 빈도표 만드는 작업 생략하고 원자료를 이용해 곧바로 빈도 막대 그래프 만듦
# 빈도 막대 그래프 만들기
sns.countplot(data = mpg, x = 'drv')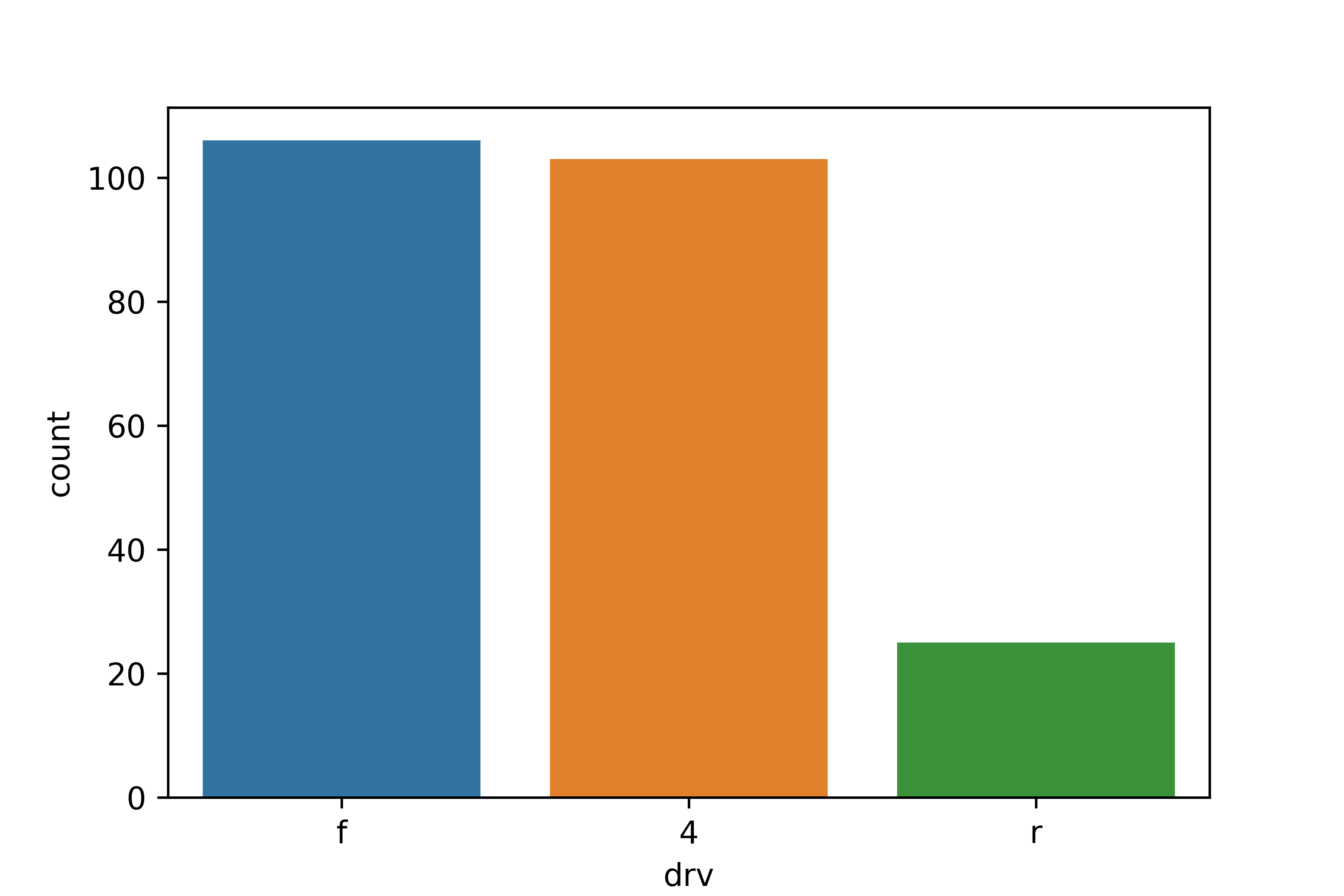
막대 정렬하기
# 4, f, r 순으로 막대 정렬
sns.countplot(data = mpg, x = 'drv', order = ['4', 'f', 'r'])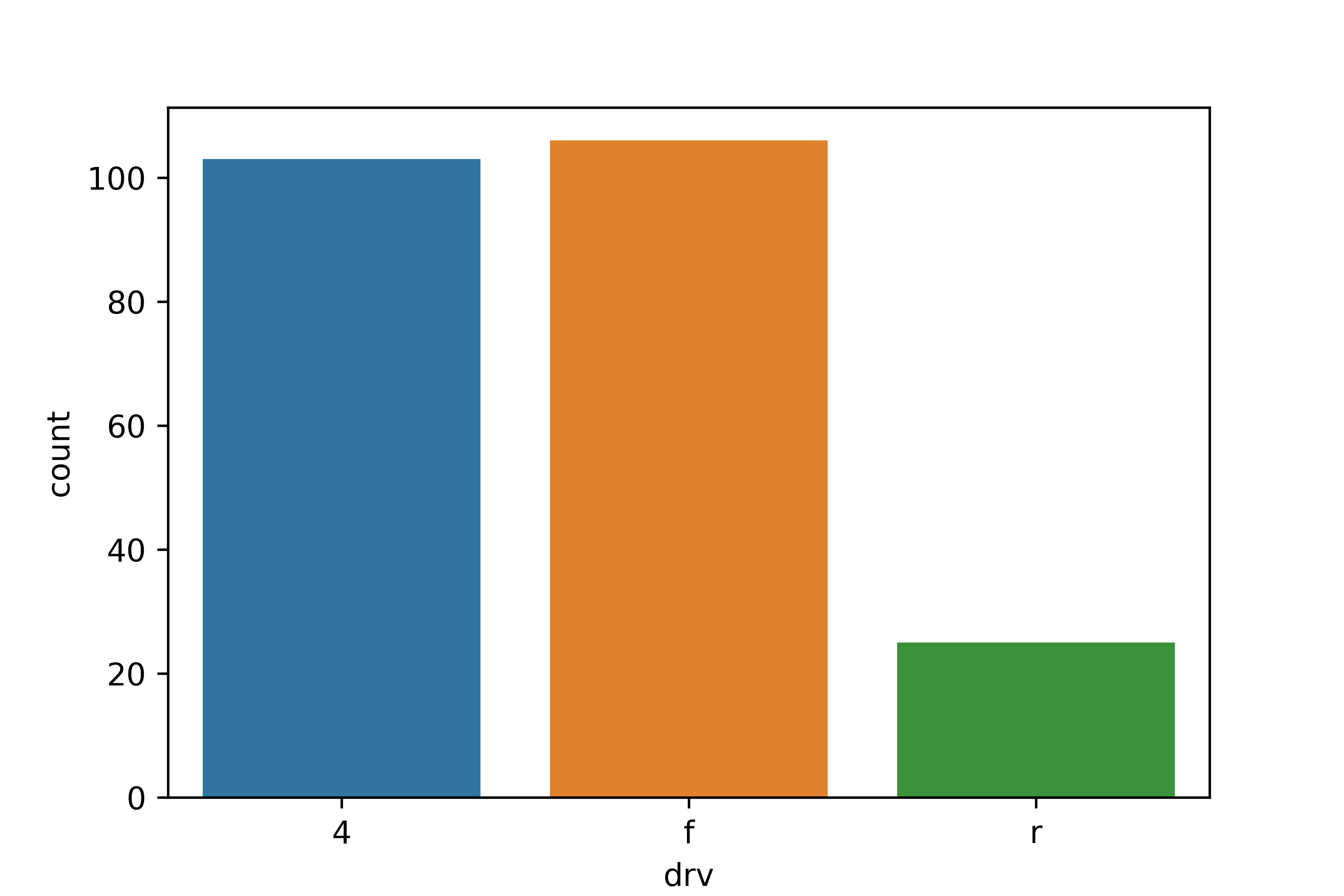
빈도 높은 순으로 정렬하기
# drv의 값을 빈도가 높은 순으로 출력
mpg['drv'].value_counts().indexIndex(['f', '4', 'r'], dtype='object', name='drv')# drv 빈도 높은 순으로 막대 정렬
sns.countplot(data = mpg, x = 'drv', order = mpg['drv'].value_counts().index)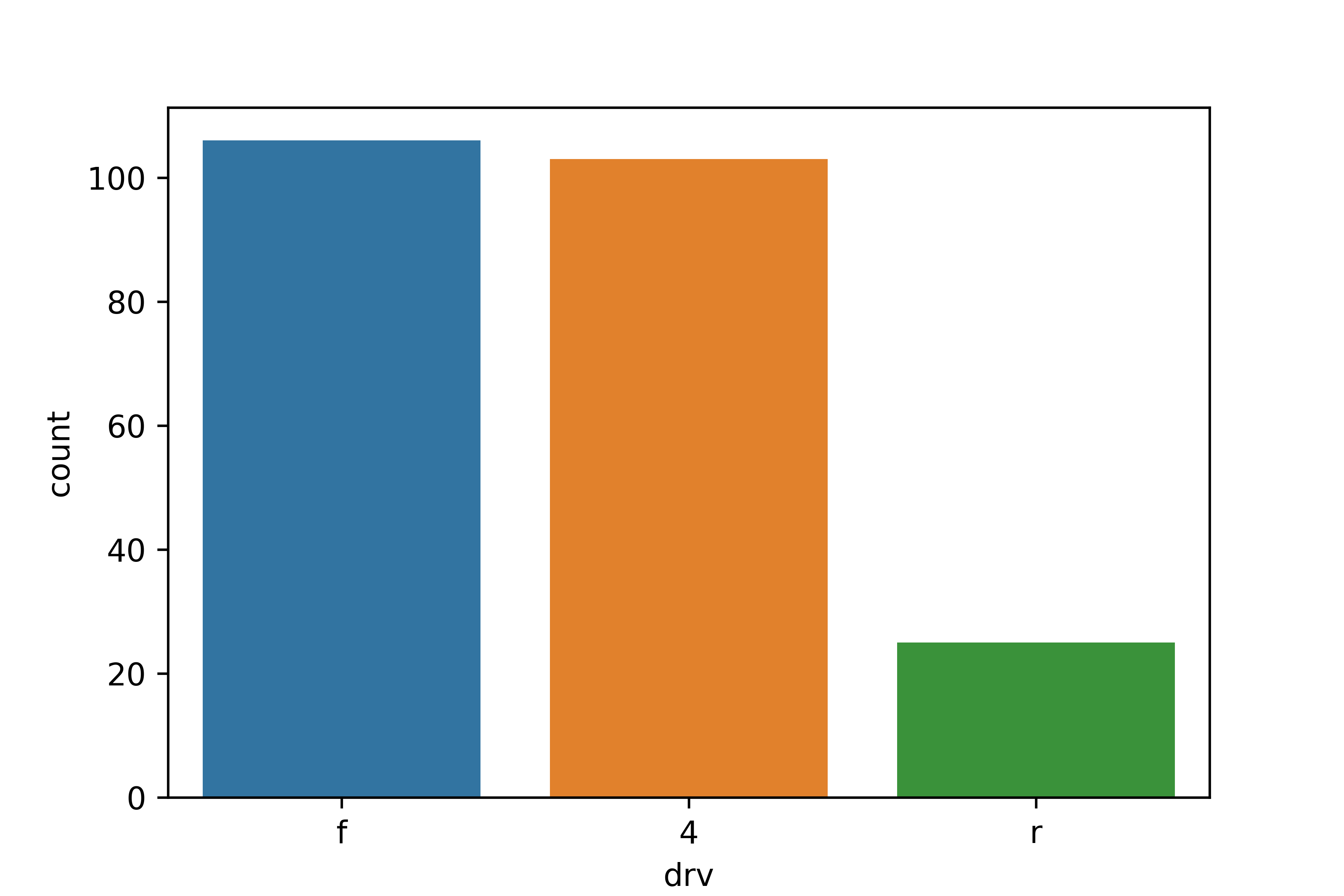
Q1. 어떤 회사에서 생산한 'suv' 차종의 도시 연비가 높은지 알아보려고 합니다. 'suv' 차종을
대상으로 cty(도시 연비) 평균이 가장 높은 회사 다섯 곳을 막대 그래프로 표현해 보세요.
막대는 연비가 높은 순으로 정렬하세요.
# 막대 그래프 만들기
sns.barplot(data = df, x = 'manufacturer', y = 'mean_cty')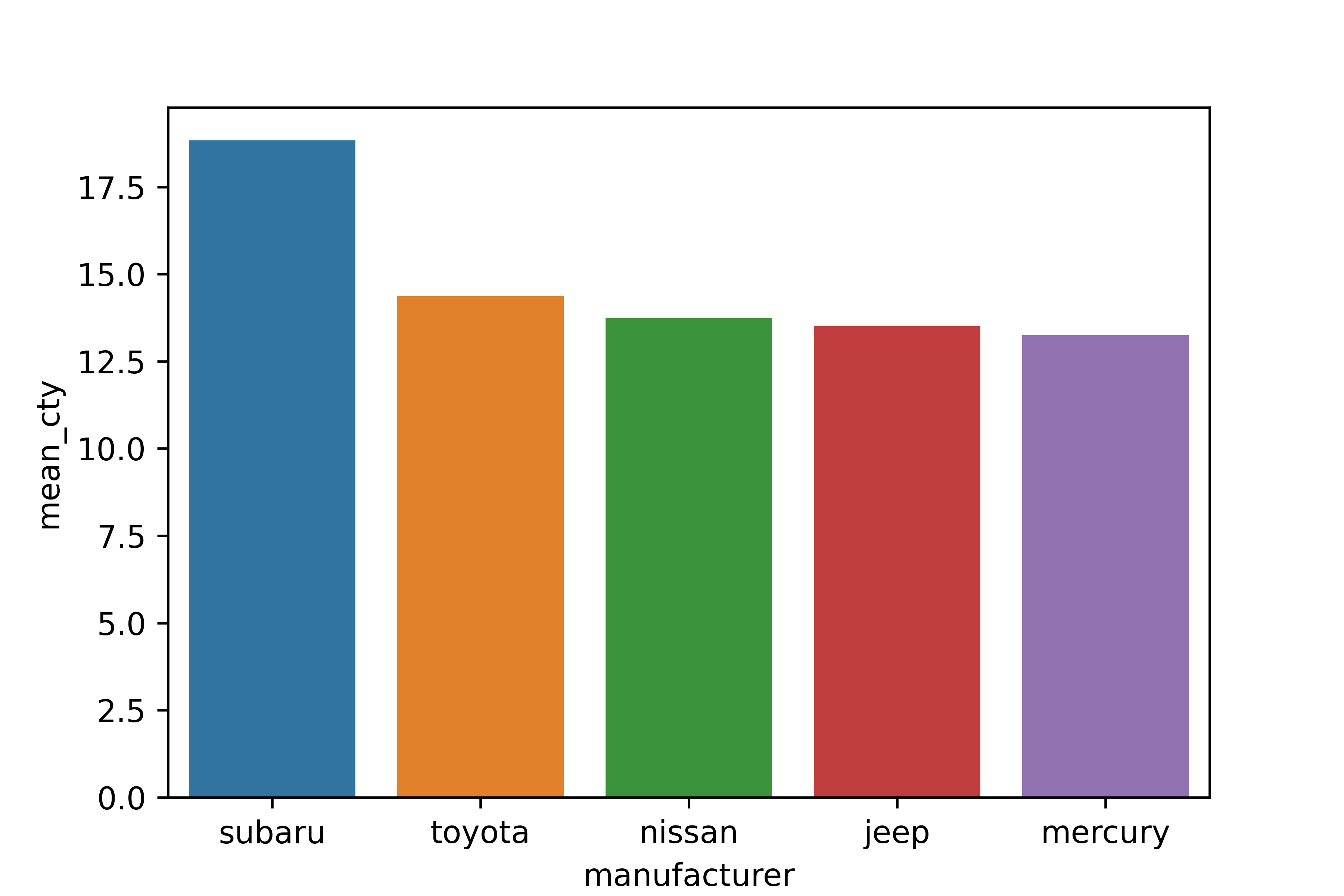
Q2. 자동차 중에 어떤 category(자동차 종류)가 많은지 알아보려고 합니다. sns.barplot()을
이용해 자동차 종류별 빈도를 표현한 막대 그래프를 만들어 보세요. 막대는 빈도가 높은 순으로
정렬하세요.
# 막대 그래프 만들기
sns.barplot(data = df_mpg, x = 'category', y = 'n')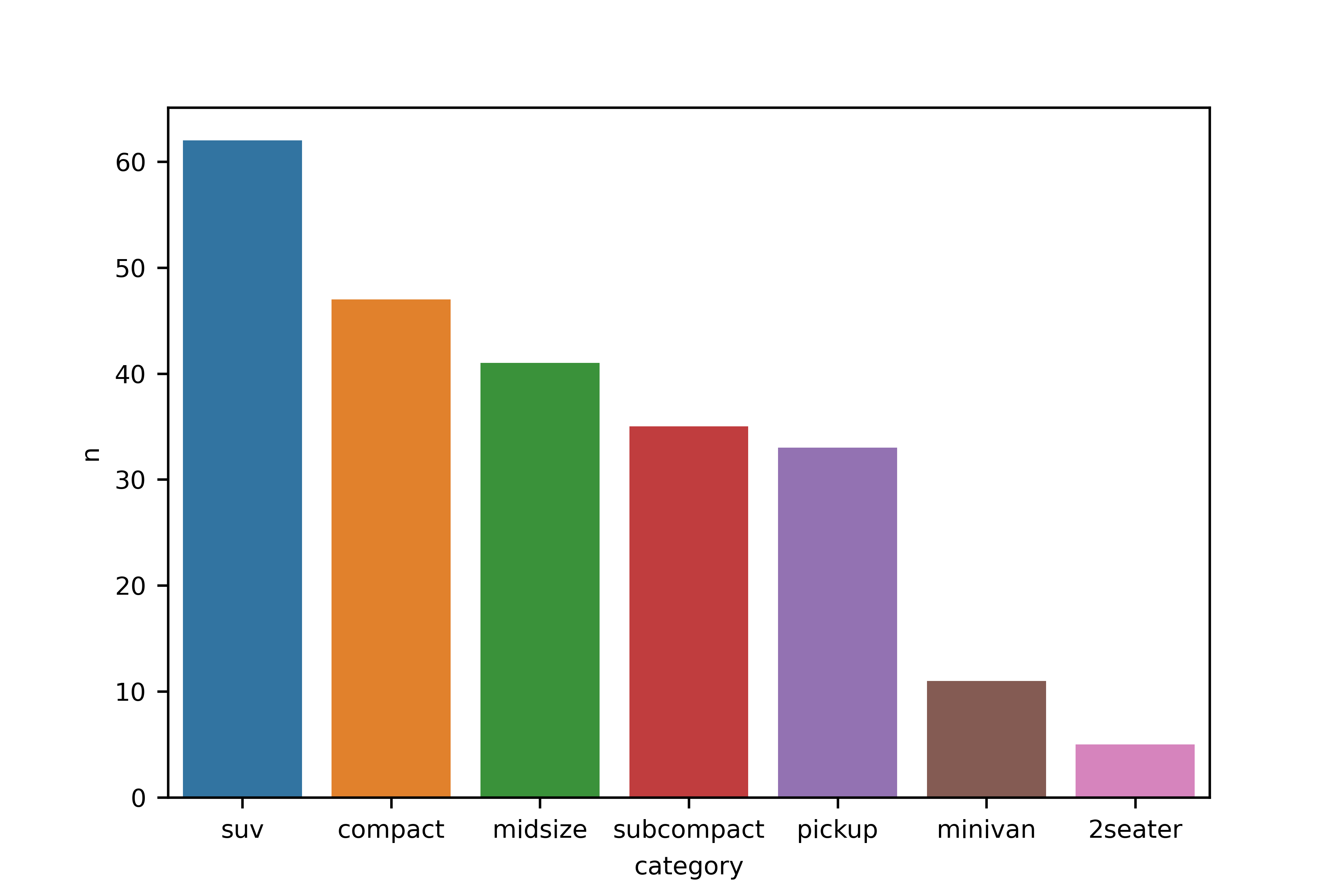
선 그래프(line chart): 데이터를 선으로 표현한 그래프
- 시간에 따라 달라지는 데이터를 표현할 때 사용
- ex) 환율, 주가지수 등 경제지표가 시간에 따라 변하는 양상
- 시계열 데이터(time series data): 일별 환율처럼, 일정 시간 간격을 두고 나열된 데이터
- 시계열 그래프(time series chart): 시계열 데이터를 선으로 표현한 그래프
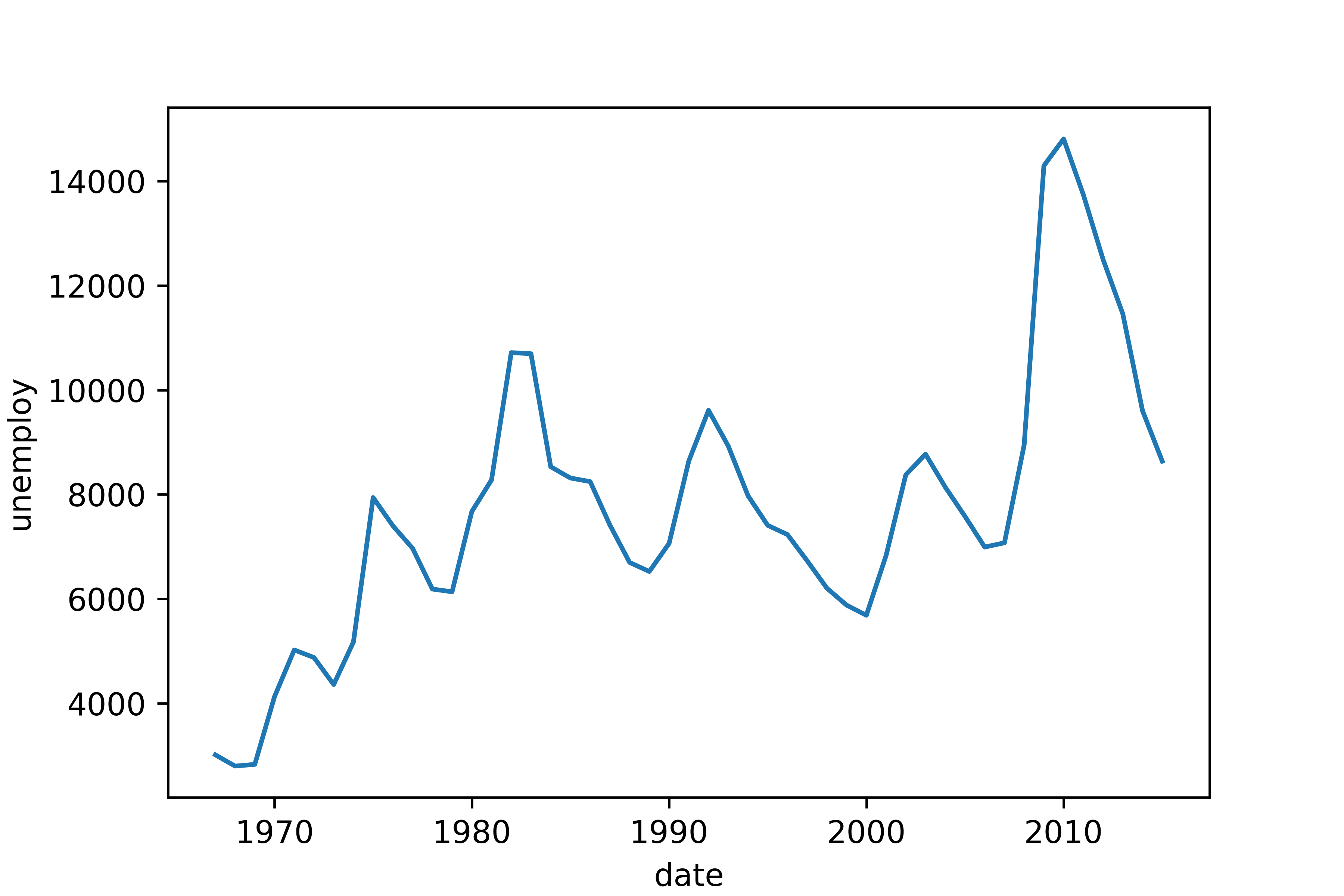
sns.lineplot(data = economics, x = 'date', y = 'unemploy')
- x축에 굵은 선이 표시되어 있음
- ‘연월일’ 을 나타낸 문자가 x축에 여러 번 겹쳐 표시되었기 때문
(3) x축에 연도 표시하기
# x축에 연도 표시
sns.lineplot(data = economics, x = 'year', y = 'unemploy')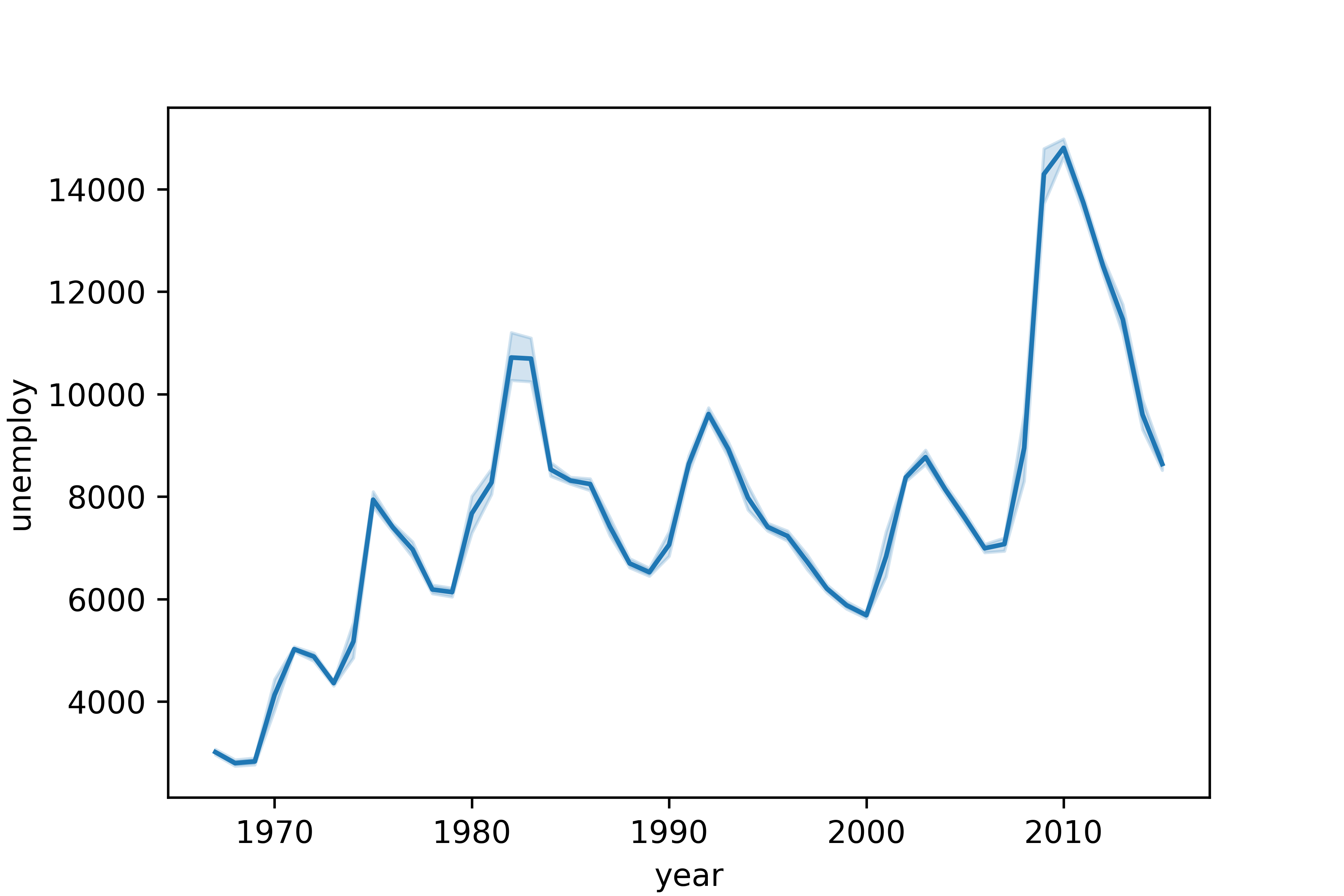
(3) x축에 연도 표시하기
# 신뢰구간 제거
sns.lineplot(data = economics, x = 'year', y = 'unemploy', errorbar = None)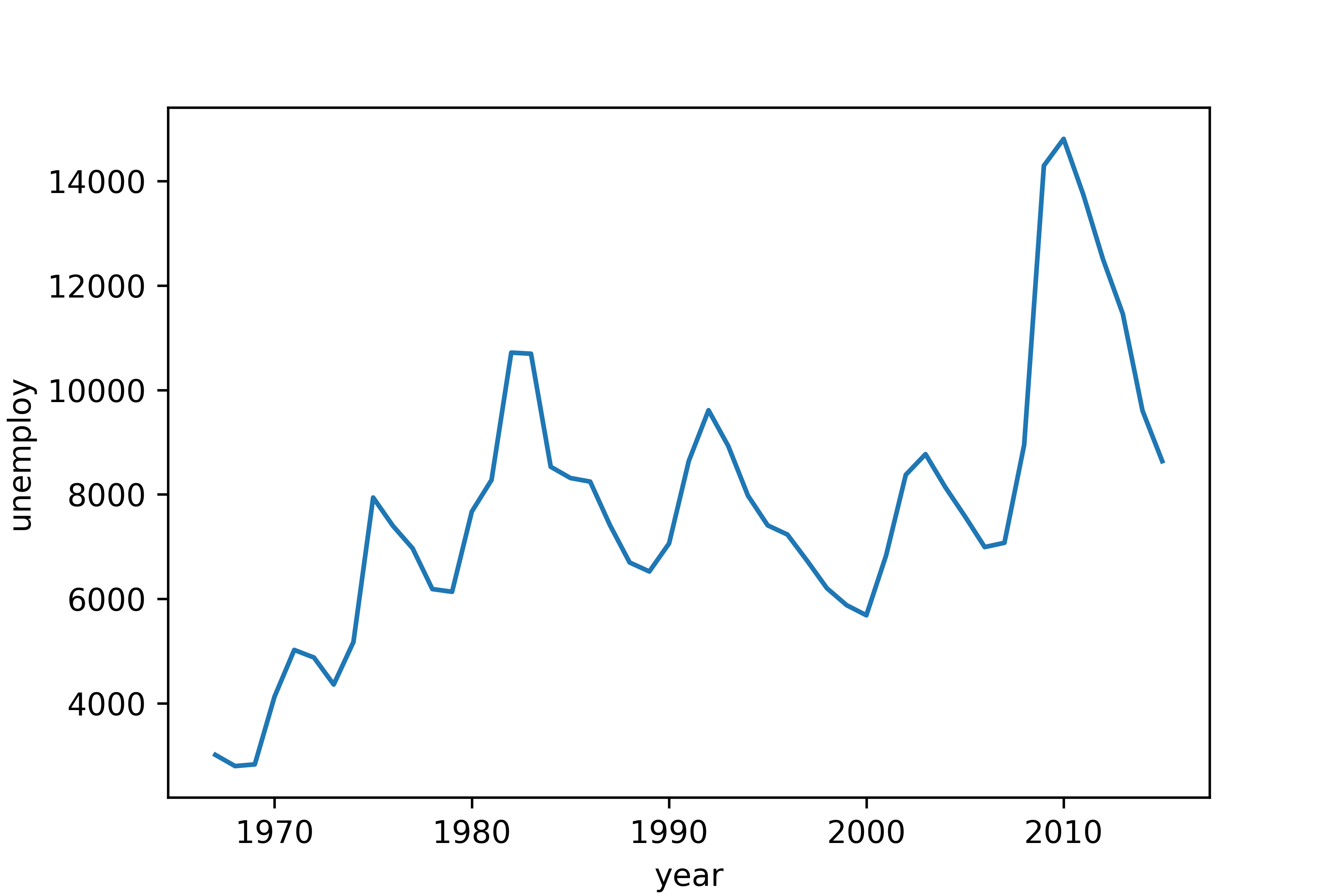
Q1. psavert(개인 저축률)가 시간에 따라 어떻게 변해 왔는지 알아보려고 합니다.
연도별 개인 저축률의 변화를 나타낸 시계열 그래프를 만들어 보세요.
# 연도별 개인 저축률 선 그래프
sns.lineplot(data = economics, x = 'year', y = 'psavert', errorbar = None)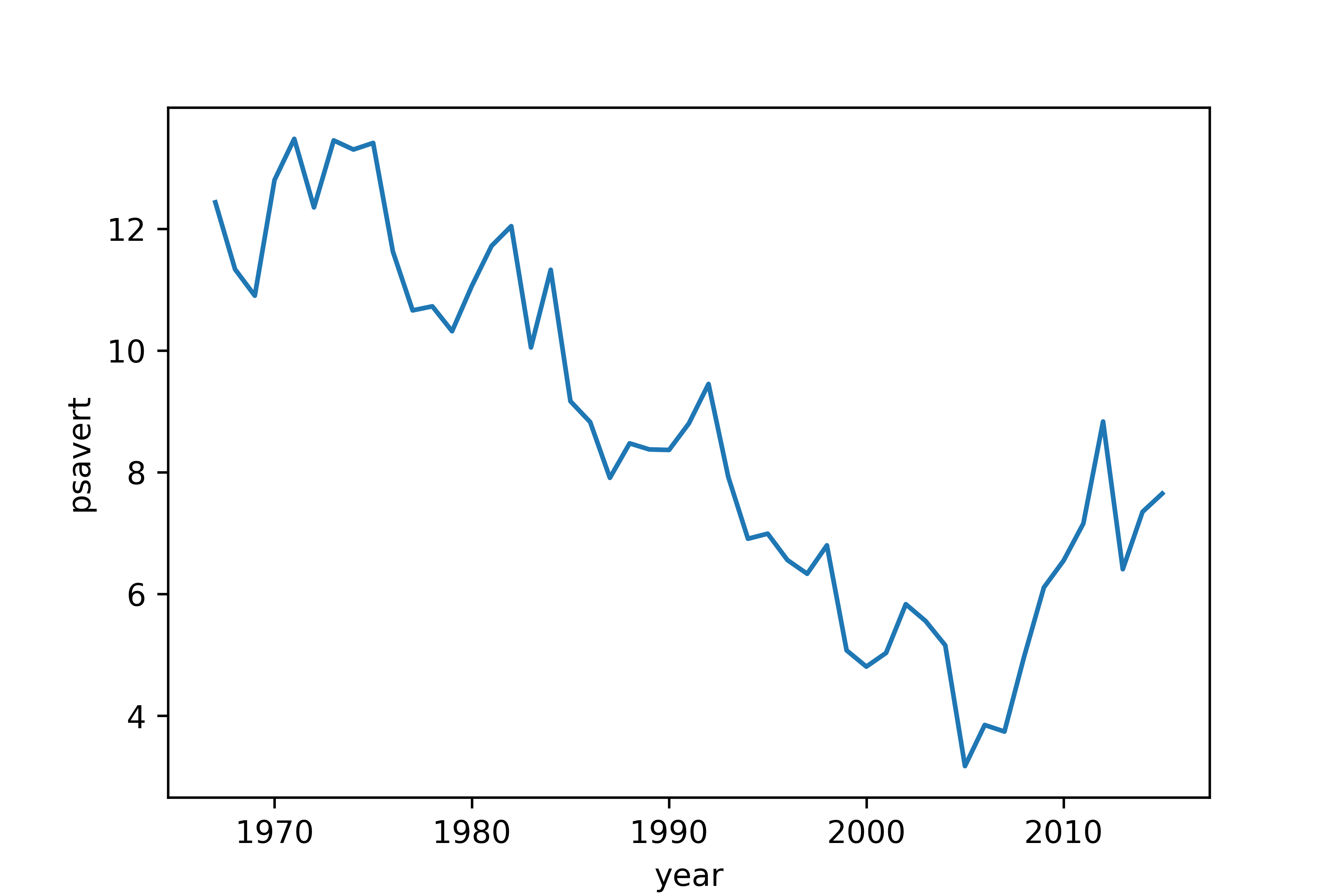
Q2. 2014년 월별 psavert의 변화를 나타낸 시계열 그래프를 만들어 보세요.
# 월 변수 추가
economics['month'] = economics['date2'].dt.month
# 2014년 추출
df_2014 = economics.query('year == 2014')
# 선 그래프 만들기
sns.lineplot(data = df_2014, x = 'month', y = 'psavert', errorbar = None)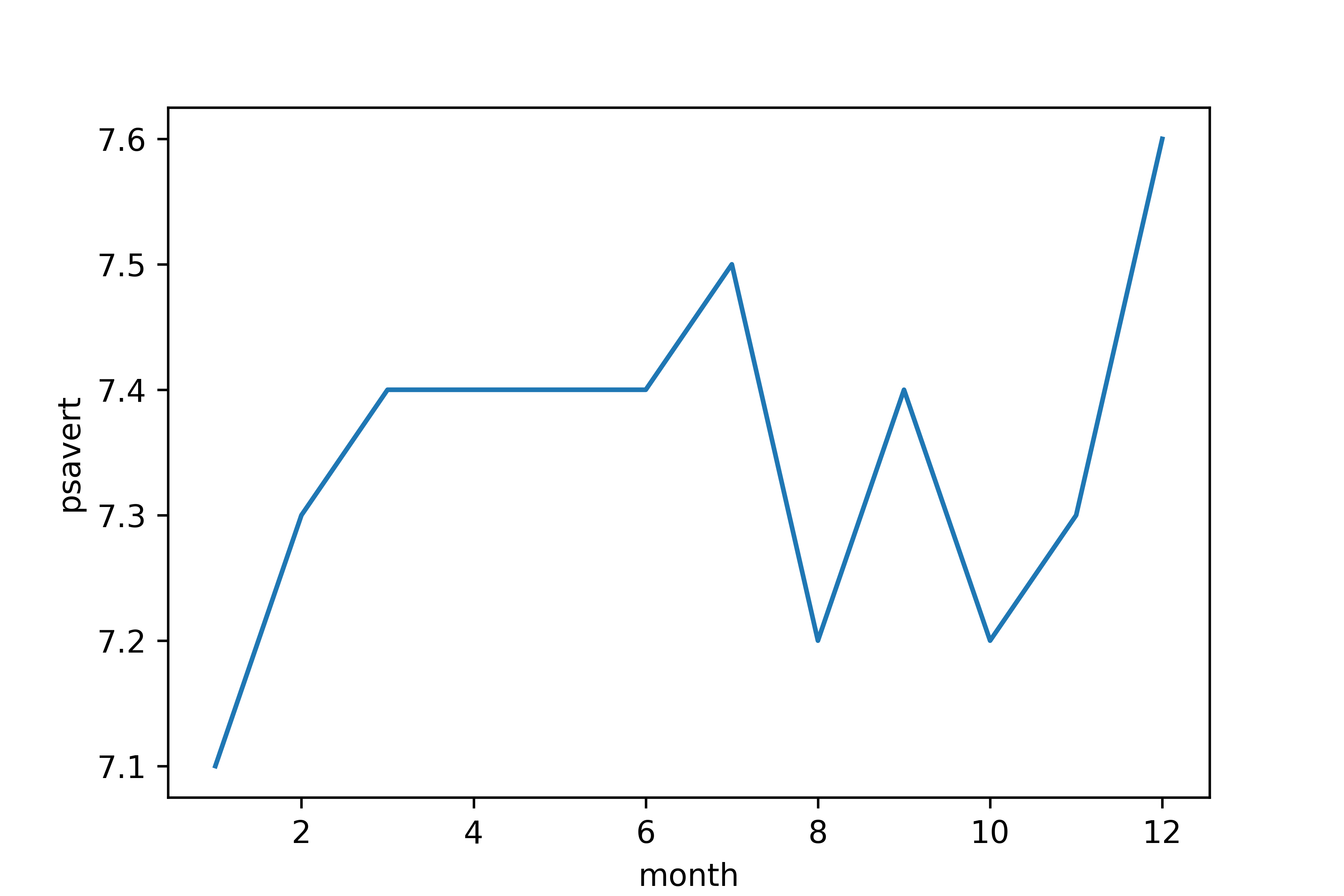
상자 그림(box plot) : 데이터의 분포 또는 퍼져 있는 형태를 직사각형 상자 모양으로 표현한 그래프
- 데이터가 어떻게 분포하고 있는지 알 수 있다
- 평균값만 볼 때보다 데이터의 특징을 더 자세히 이해할 수 있댜
상자 그림 만들기
sns.boxplot(data = mpg, x = 'drv', y = 'hwy')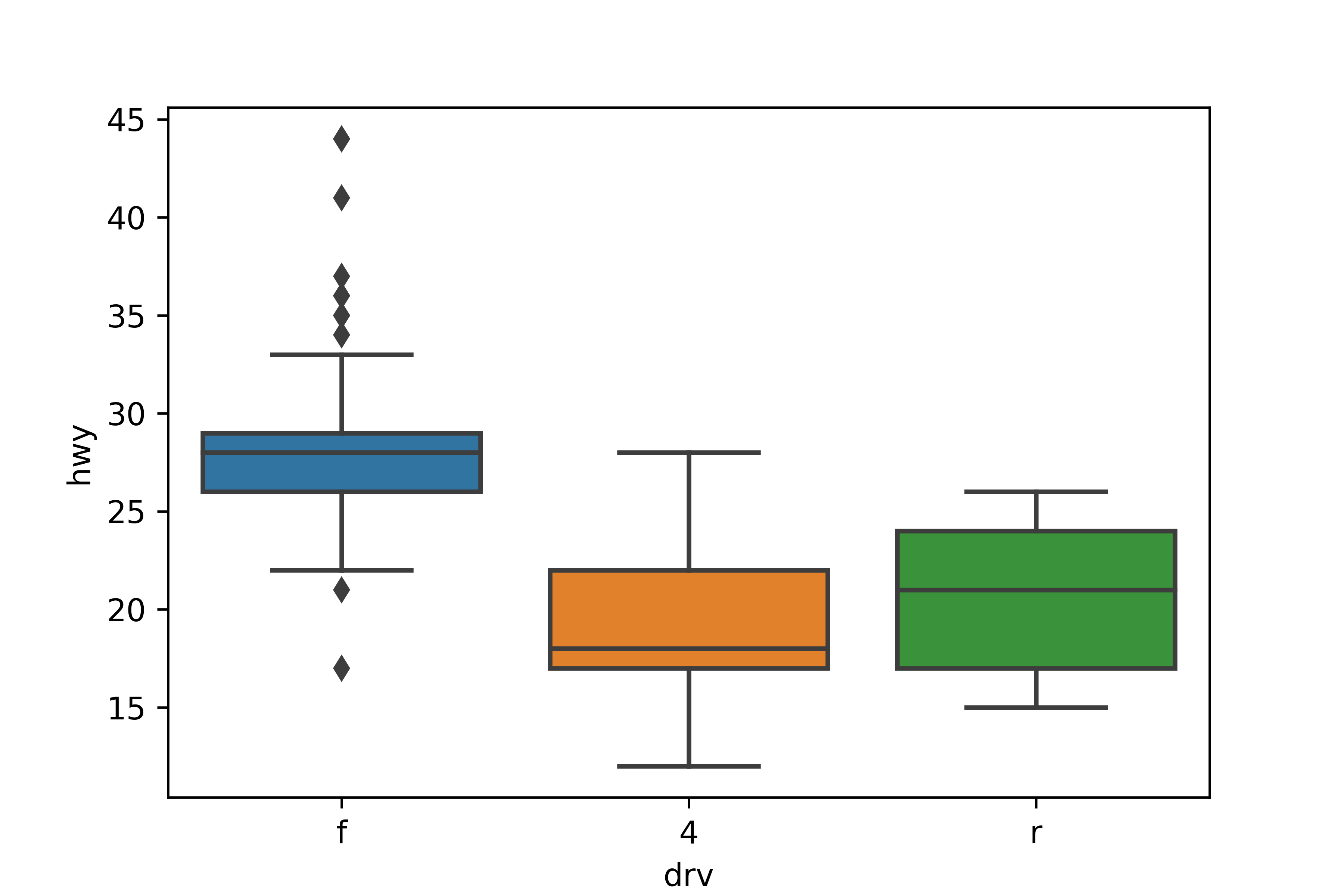
상자 그림 만들기
sns.boxplot(data = mpg, x = 'drv', y = 'hwy')
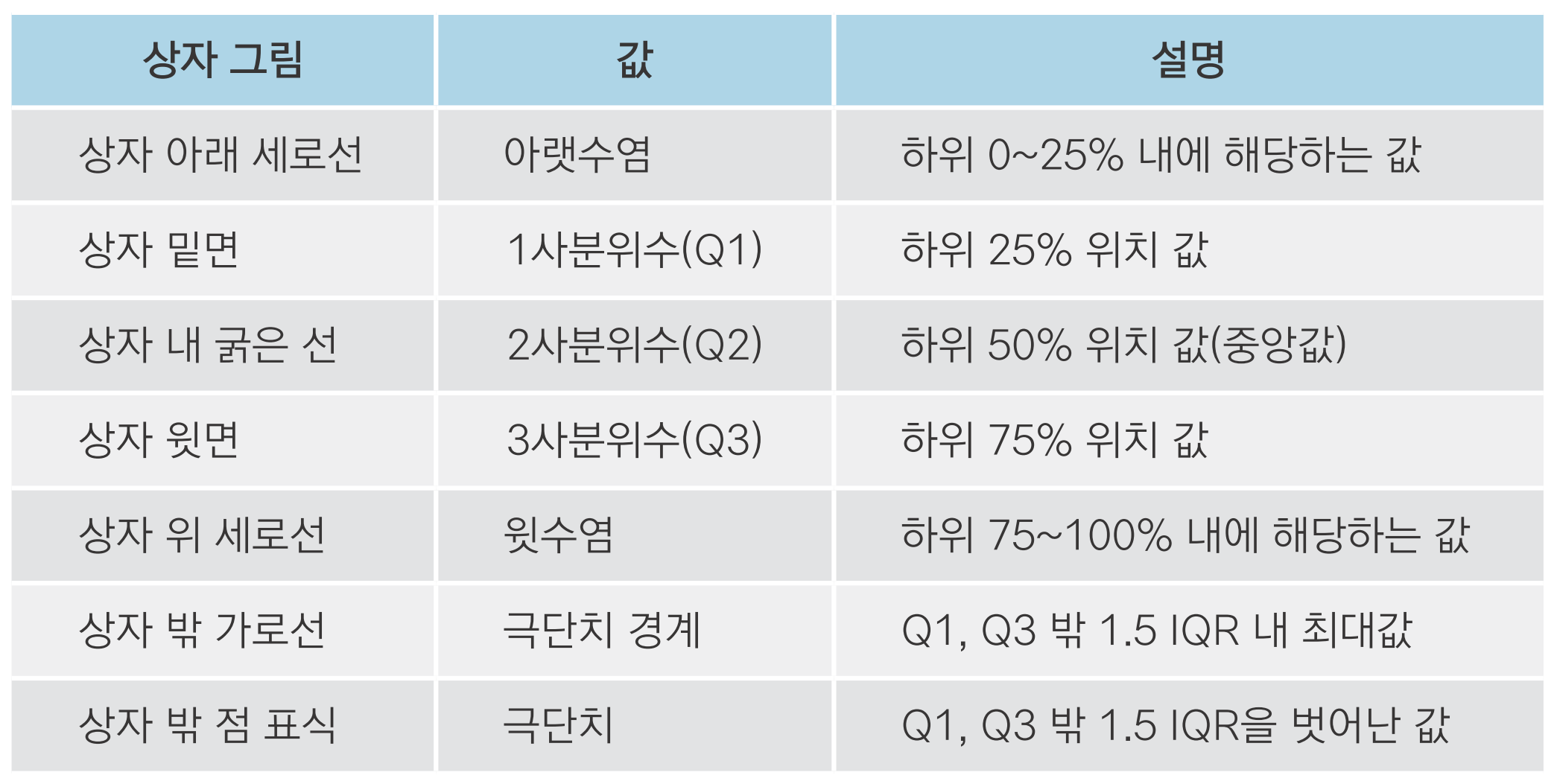
• IQR(사분위 범위): 1사분위수와 3사분위수의 거리
상자 그림 만들기
sns.boxplot(data = mpg, x = 'drv', y = 'hwy')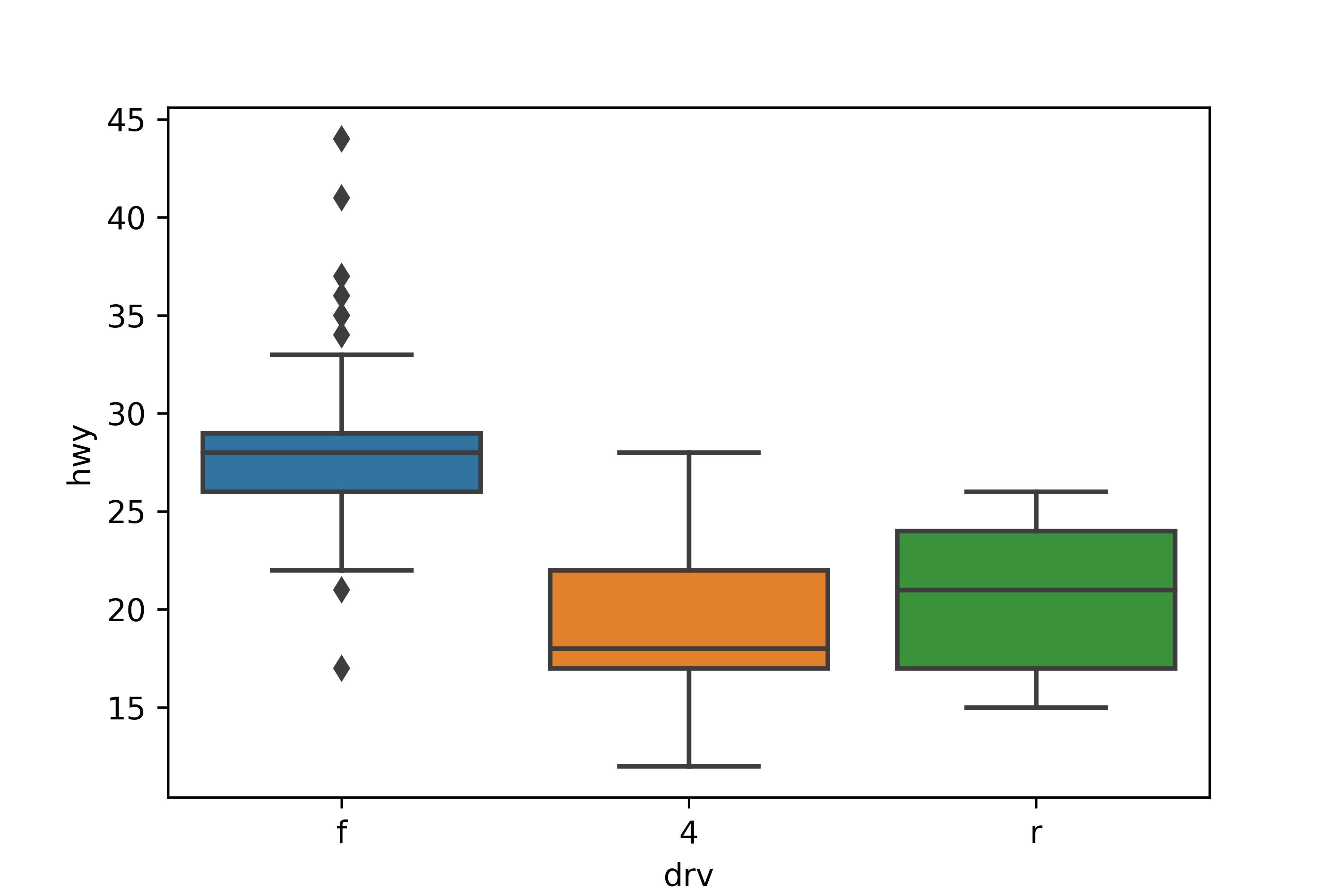
- 전륜구동(f)
- 26~29 사이의 좁은 범위에 자동차가 모여 있는 뾰족한 형태의 분포
- 수염의 위아래에 점 표식이 있으므로 연비가
극단적으로 높거나 낮은 자동차들이 있다
- 4륜구동(4)
- 17~22 사이에 자동차 대부분이 모여 있다
- 중앙값이 상자 밑면에 가까우므로 낮은 값 쪽으로 치우친 형태의 분포
- 후륜구동(r)
- 17~24 사이의 넓은 범위에 자동차가 분포한다
- 수염이 짧고 극단치가 없으므로 자동차 대부분이 사분위 범위에 해당
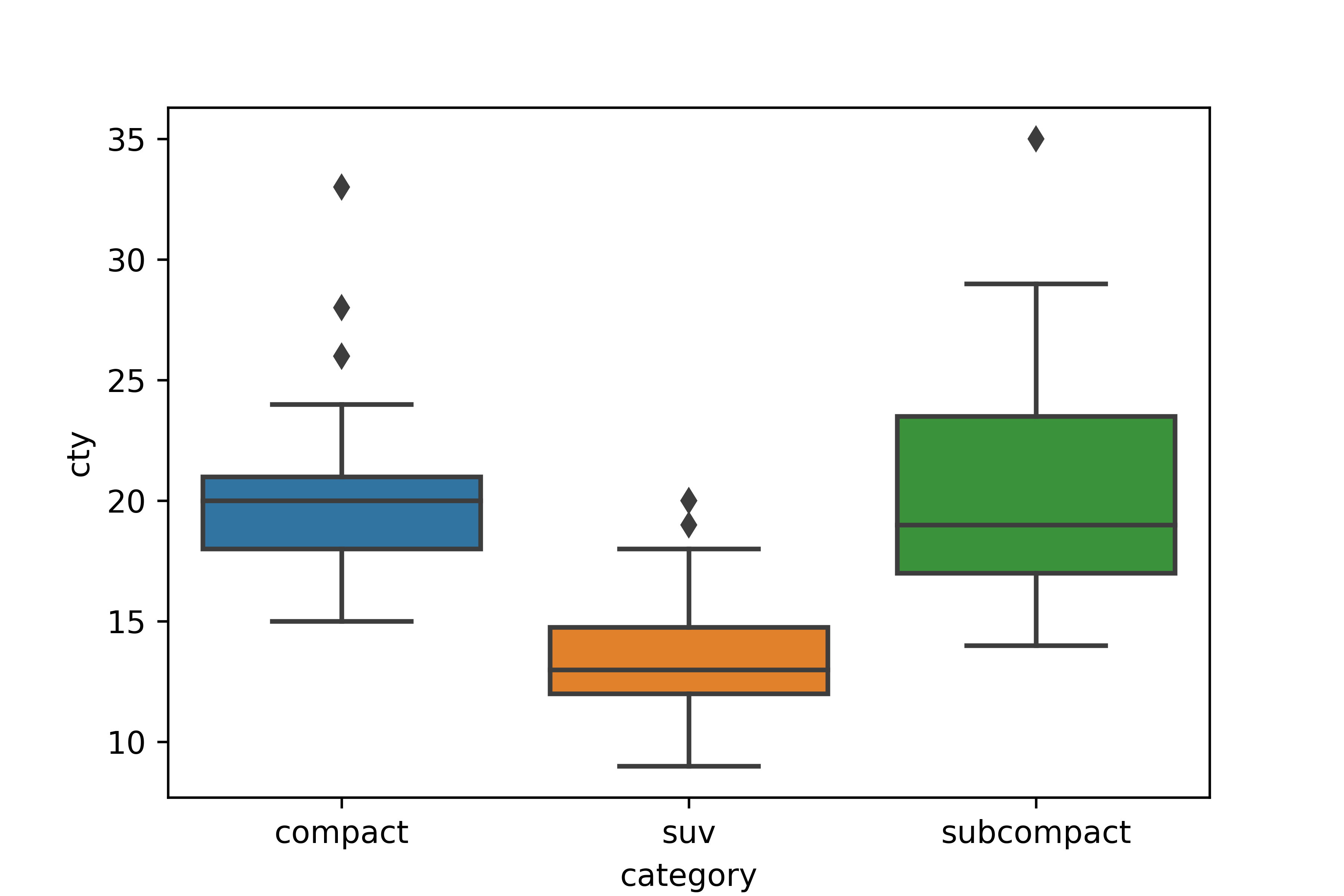
Q1. category(자동차 종류)가 'compact', 'subcompact', 'suv'인 자동차의 cty(도시 연비)가
어떻게 다른지 비교해 보려고 합니다. 세 차종의 cty를 나타낸 상자 그림을 만들어 보세요.
# mpg 데이터 불러오기
mpg = pd.read_csv('mpg.csv')
# compact, subcompact, suv 차종 추출
df = mpg.query('category in ["compact", "subcompact", "suv"]')
# 상자 그림 만들기
sns.boxplot(data = df, x = 'category', y = 'cty')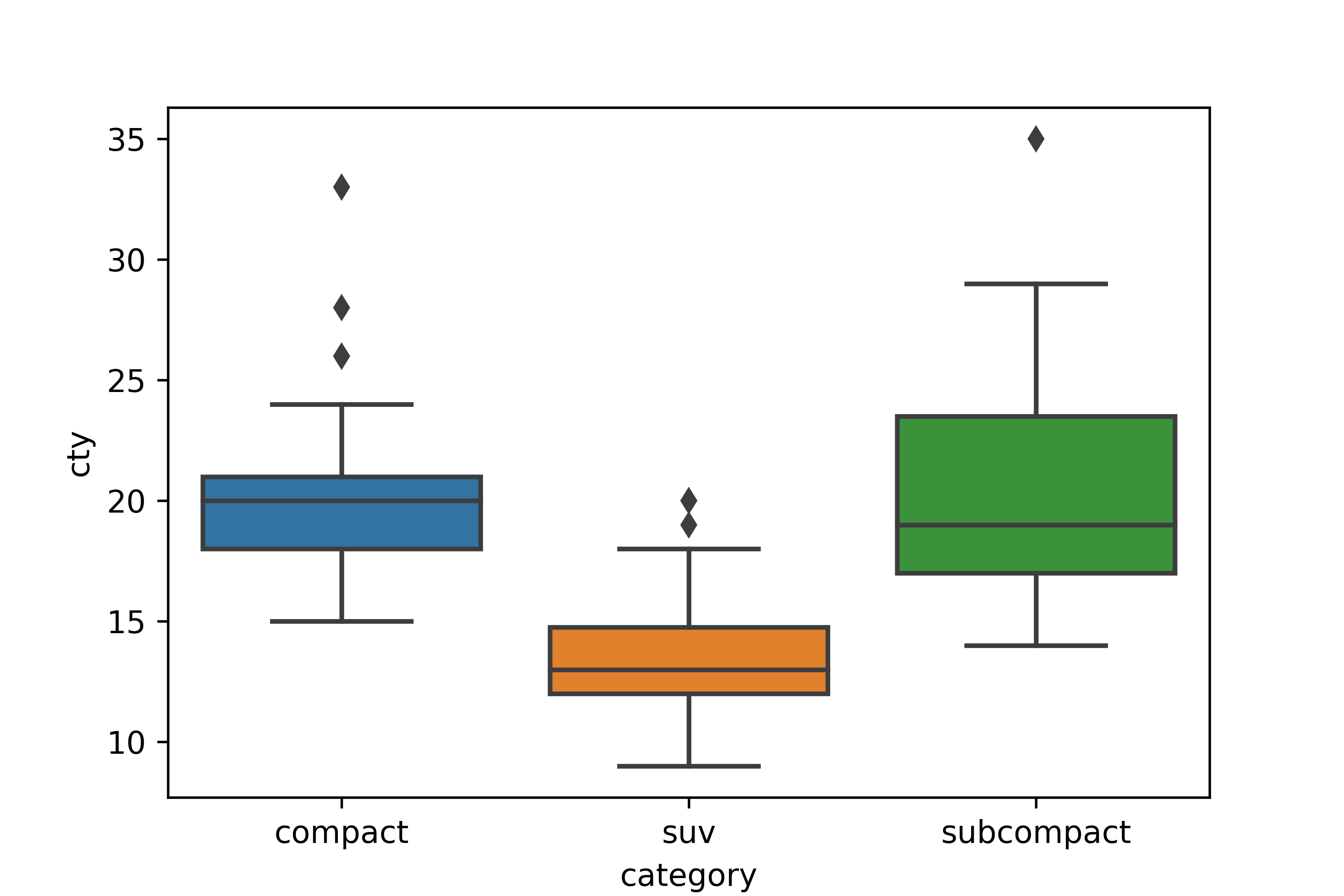
정리하기