import pandas as pd
exam = pd.read_csv('exam.csv')Do it! 쉽게 배우는 파이썬 데이터 분석
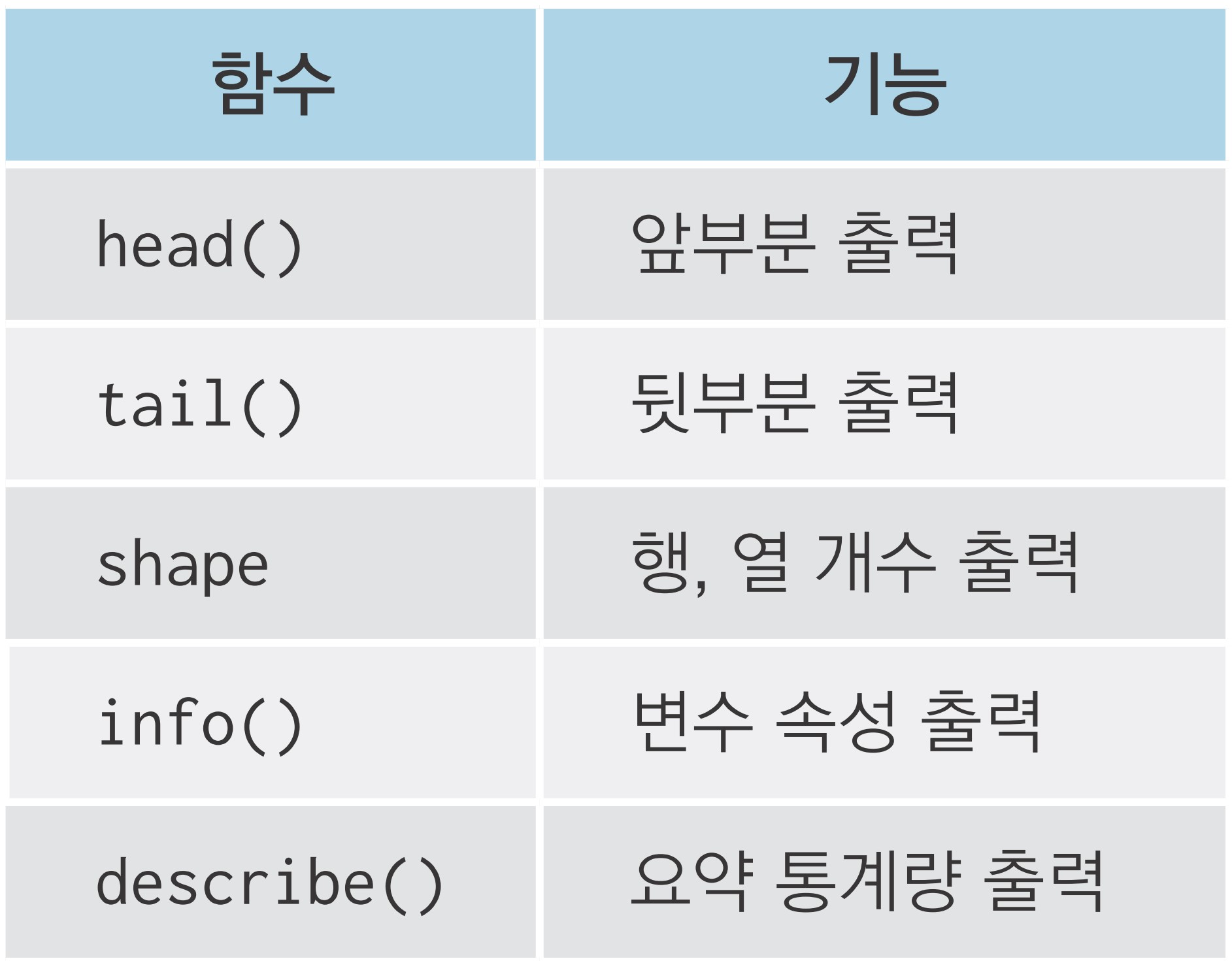
데이터를 파악할 때 사용하는 명령어
describe() - 요약 통계량 구하기
exam.describe() id nclass math english science
count 20.00000 20.000000 20.000000 20.000000 20.000000
mean 10.50000 3.000000 57.450000 84.900000 59.450000
std 5.91608 1.450953 20.299015 12.875517 25.292968
min 1.00000 1.000000 20.000000 56.000000 12.000000
25% 5.75000 2.000000 45.750000 78.000000 45.000000
50% 10.50000 3.000000 54.000000 86.500000 62.500000
75% 15.25000 4.000000 75.750000 98.000000 78.000000
max 20.00000 5.000000 90.000000 98.000000 98.000000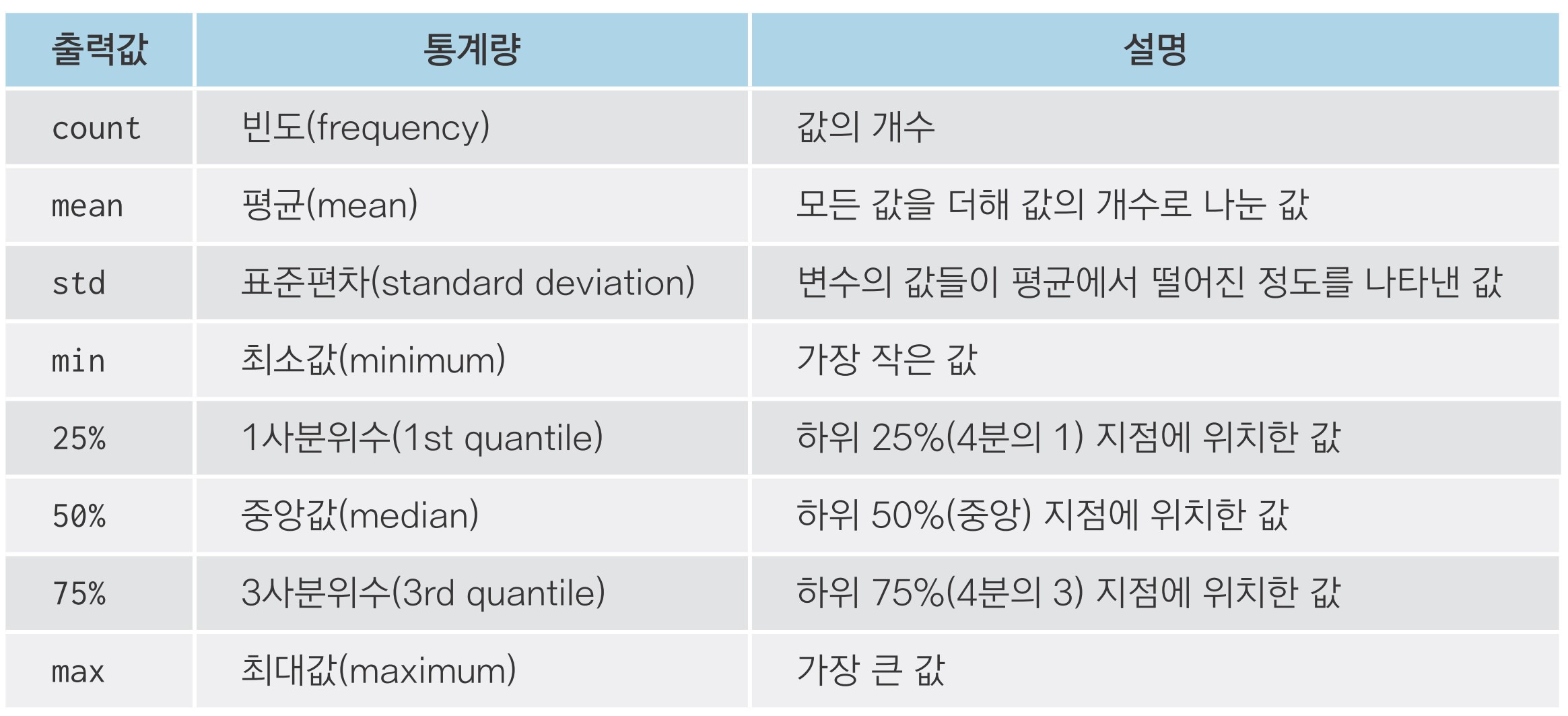
mpg.describe(include = 'all') # 문자 변수 요약 통계량 함께 출력 manufacturer model displ ... hwy fl category
count 234 234 234.000000 ... 234.000000 234 234
unique 15 38 NaN ... NaN 5 7
top dodge caravan 2wd NaN ... NaN r suv
freq 37 11 NaN ... NaN 168 62
mean NaN NaN 3.471795 ... 23.440171 NaN NaN
std NaN NaN 1.291959 ... 5.954643 NaN NaN
min NaN NaN 1.600000 ... 12.000000 NaN NaN
25% NaN NaN 2.400000 ... 18.000000 NaN NaN
50% NaN NaN 3.300000 ... 24.000000 NaN NaN
75% NaN NaN 4.600000 ... 27.000000 NaN NaN
max NaN NaN 7.000000 ... 44.000000 NaN NaN
함수와 메서드 차이 알아보기

메서드와 어트리뷰트의 차이

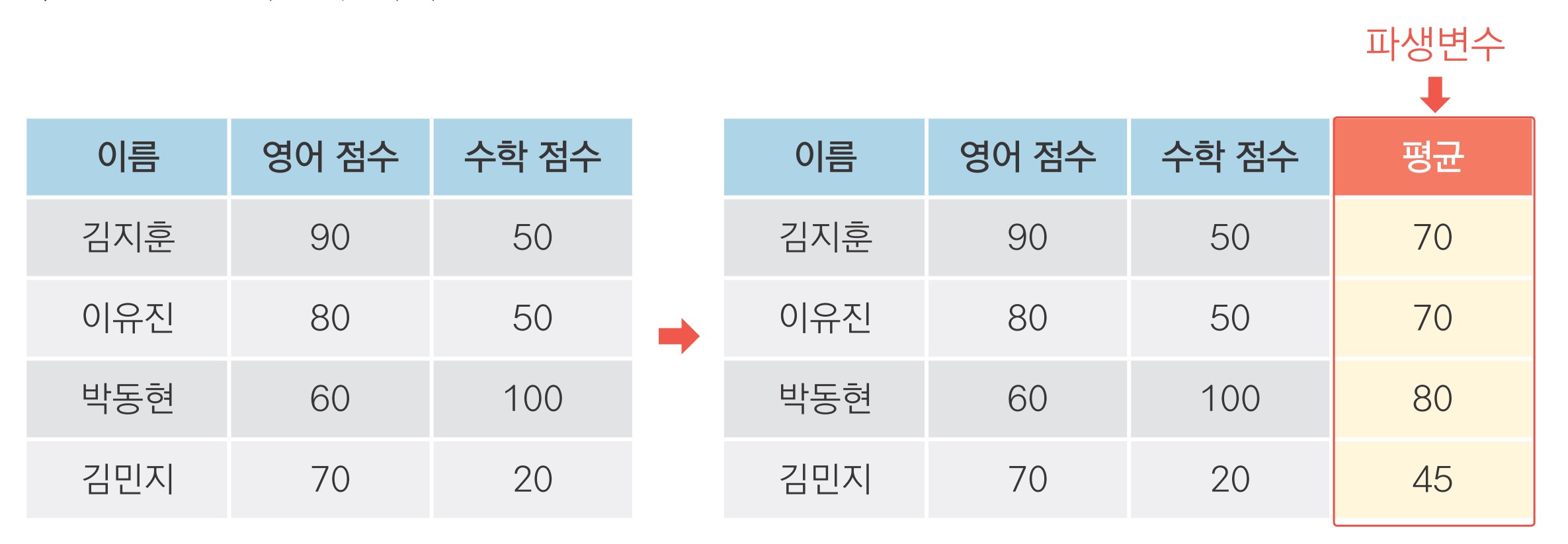
파생변수(derived variable)
- 기존의 변수를 변형해 만든 변수
mpg['total'].plot.hist() # 그래프 만들기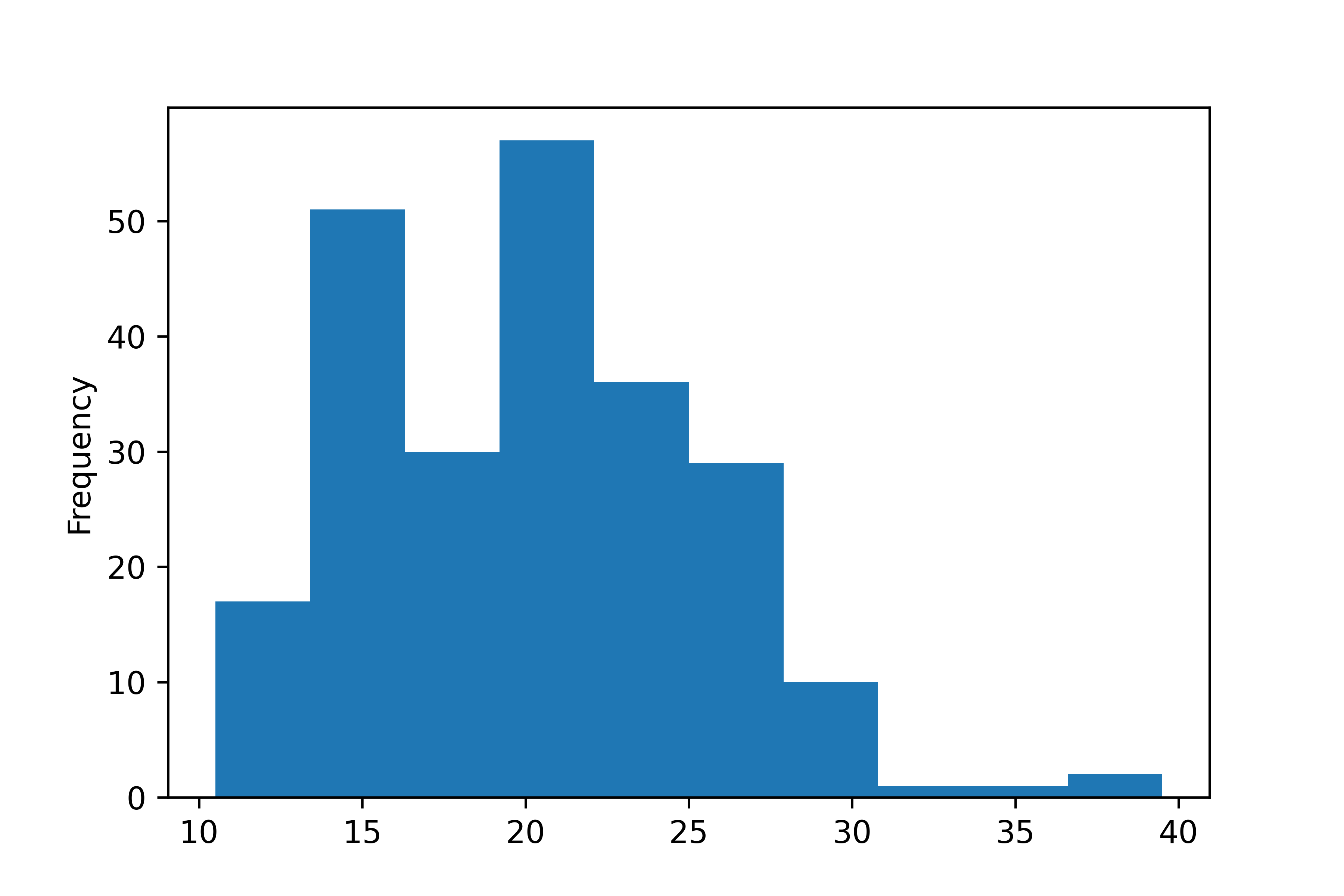
2. 합격 판정 변수 만들기

import numpy as np
# 20 이상이면 pass, 그렇지 않으면 fail 부여
mpg['test'] = np.where(mpg['total'] >= 20, 'pass', 'fail')
mpg.head() manufacturer model displ year cyl ... hwy fl category total test
0 audi a4 1.8 1999 4 ... 29 p compact 23.5 pass
1 audi a4 1.8 1999 4 ... 29 p compact 25.0 pass
2 audi a4 2.0 2008 4 ... 31 p compact 25.5 pass
3 audi a4 2.0 2008 4 ... 30 p compact 25.5 pass
4 audi a4 2.8 1999 6 ... 26 p compact 21.0 pass4. 막대 그래프로 빈도 표현하기
count_test = mpg['test'].value_counts() # 연비 합격 빈도표를 변수에 할당
count_test.plot.bar() # 연비 합격 빈도 막대 그래프 만들기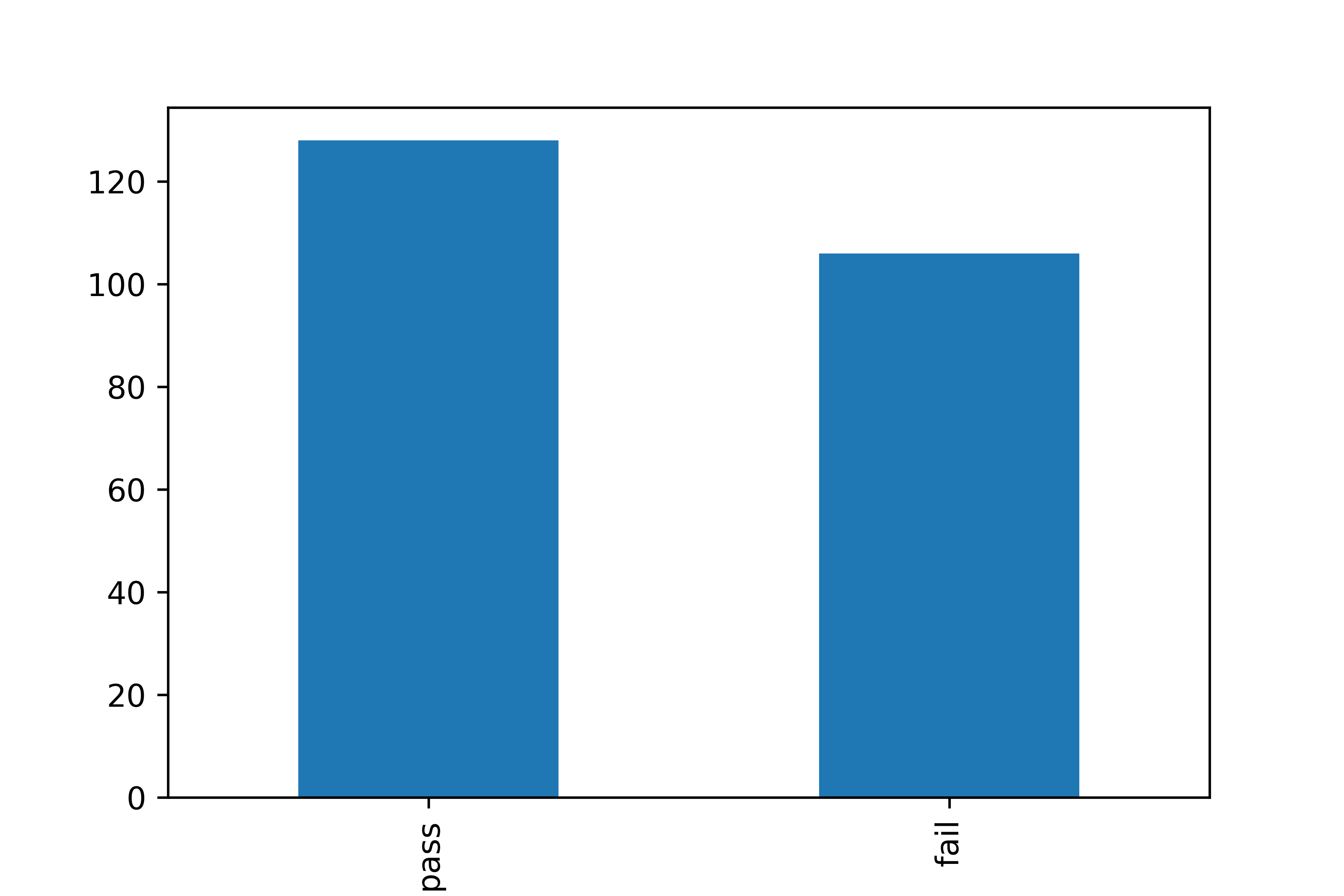
축 이름 회전하기
count_test.plot.bar(rot = 0) # 축 이름 수평으로 만들기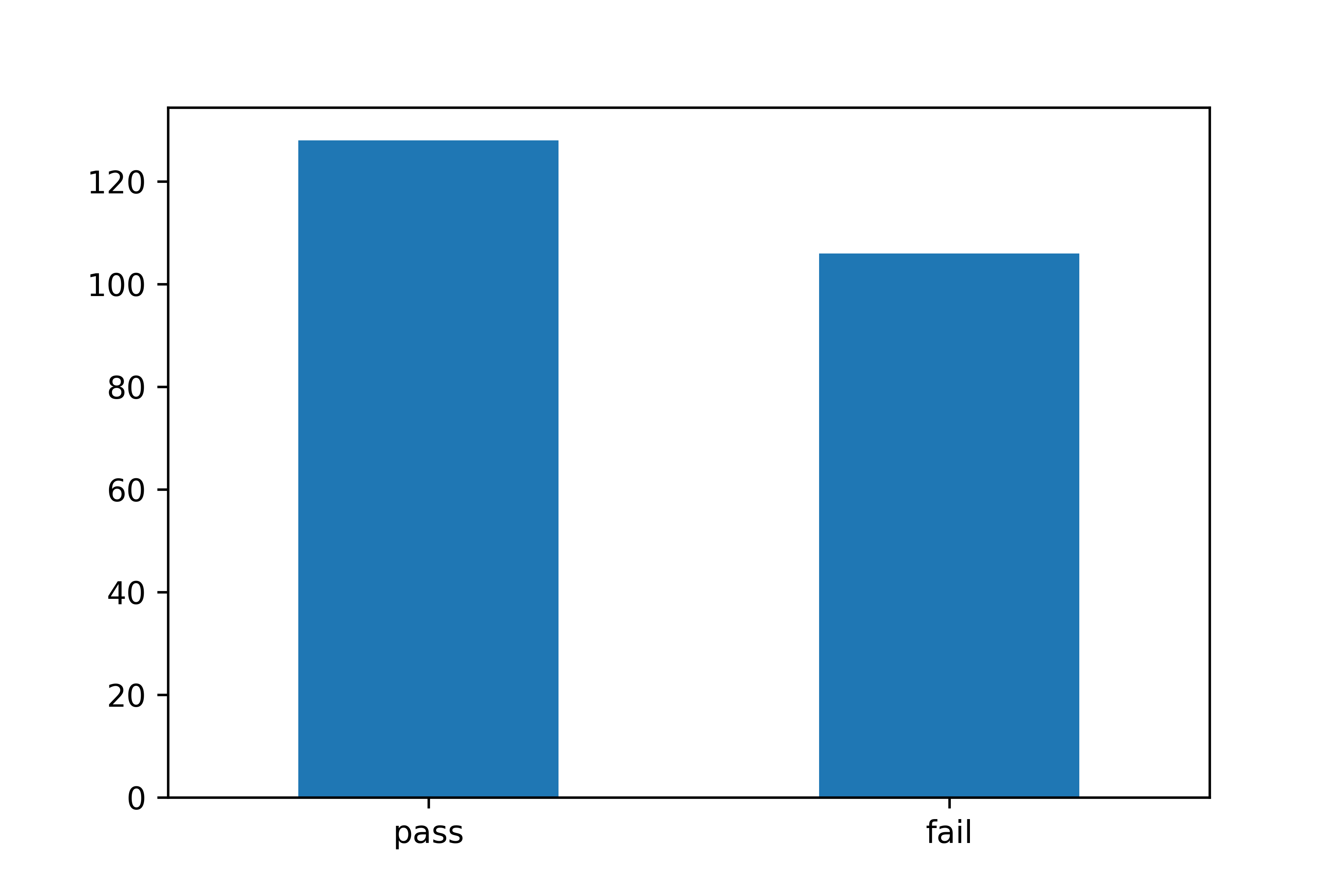
중첩 조건문 활용하기
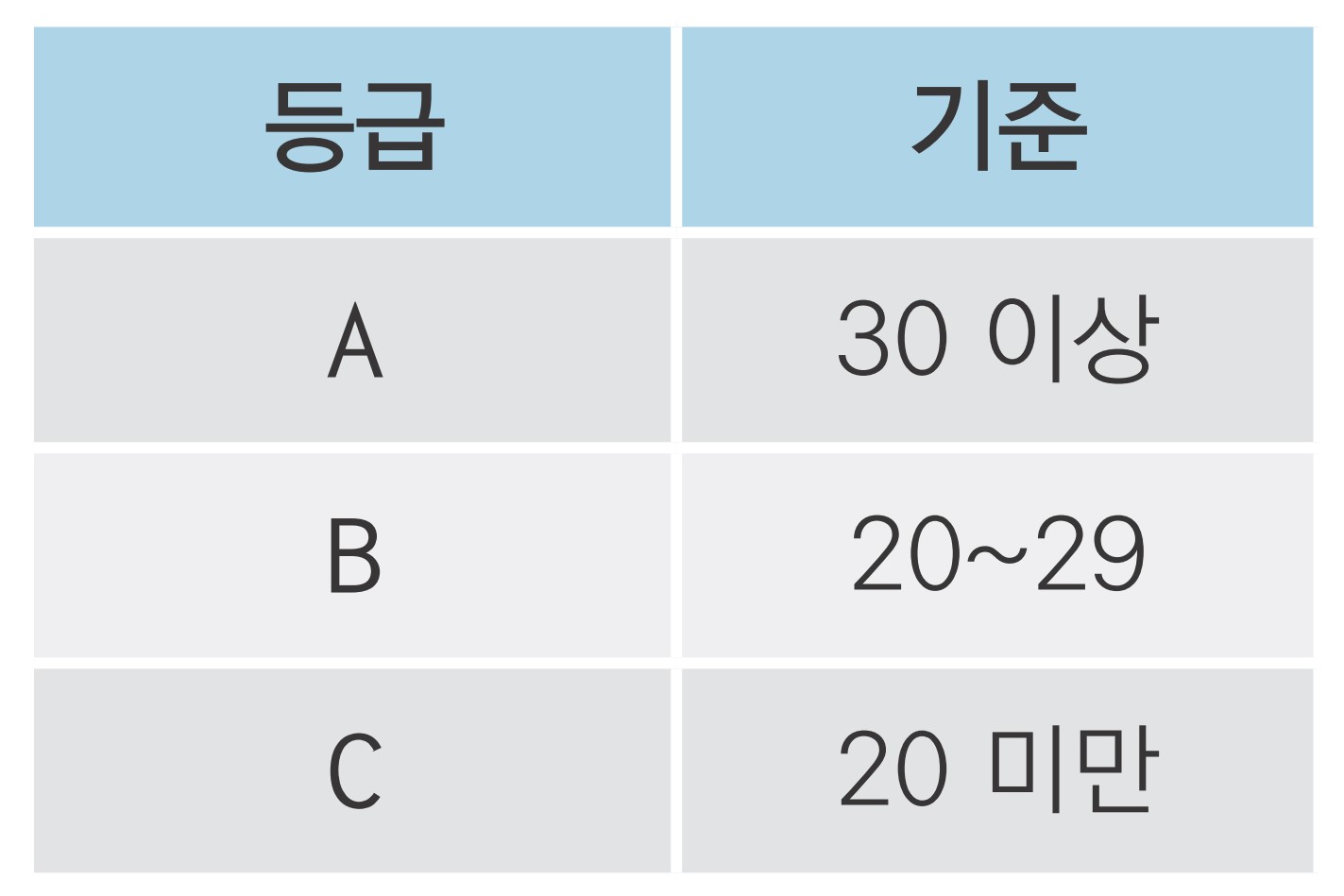
1. 연비 등급 변수 만들기
# total 기준으로 A, B, C 등급 부여
mpg['grade'] = np.where(mpg['total'] >= 30, 'A',
np.where(mpg['total'] >= 20, 'B', 'C'))
# 데이터 확인
mpg.head() manufacturer model displ year cyl ... fl category total test grade
0 audi a4 1.8 1999 4 ... p compact 23.5 pass B
1 audi a4 1.8 1999 4 ... p compact 25.0 pass B
2 audi a4 2.0 2008 4 ... p compact 25.5 pass B
3 audi a4 2.0 2008 4 ... p compact 25.5 pass B
4 audi a4 2.8 1999 6 ... p compact 21.0 pass B2. 빈도표와 막대 그래프로 연비 등급 살펴보기
count_grade = mpg['grade'].value_counts() # 등급 빈도표 만들기
count_gradeB 118
C 106
A 10
Name: grade, dtype: int64count_grade.plot.bar(rot = 0) # 등급 빈도 막대 그래프 만들기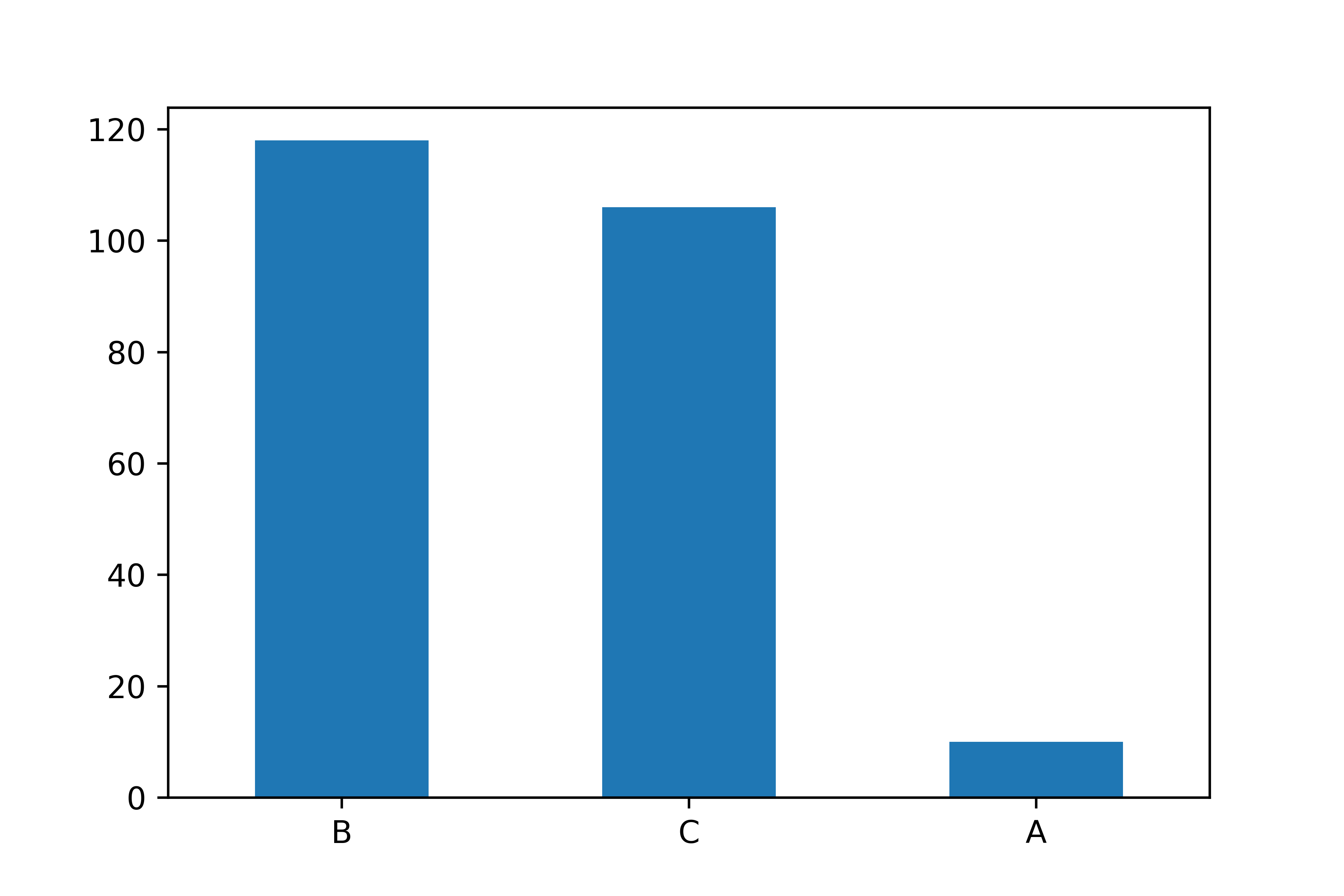
알파벳순으로 막대 정렬하기
# 등급 빈도표 알파벳순 정렬
count_grade = mpg['grade'].value_counts().sort_index()
count_gradeA 10
B 118
C 106
Name: grade, dtype: int64count_grade.plot.bar(rot = 0)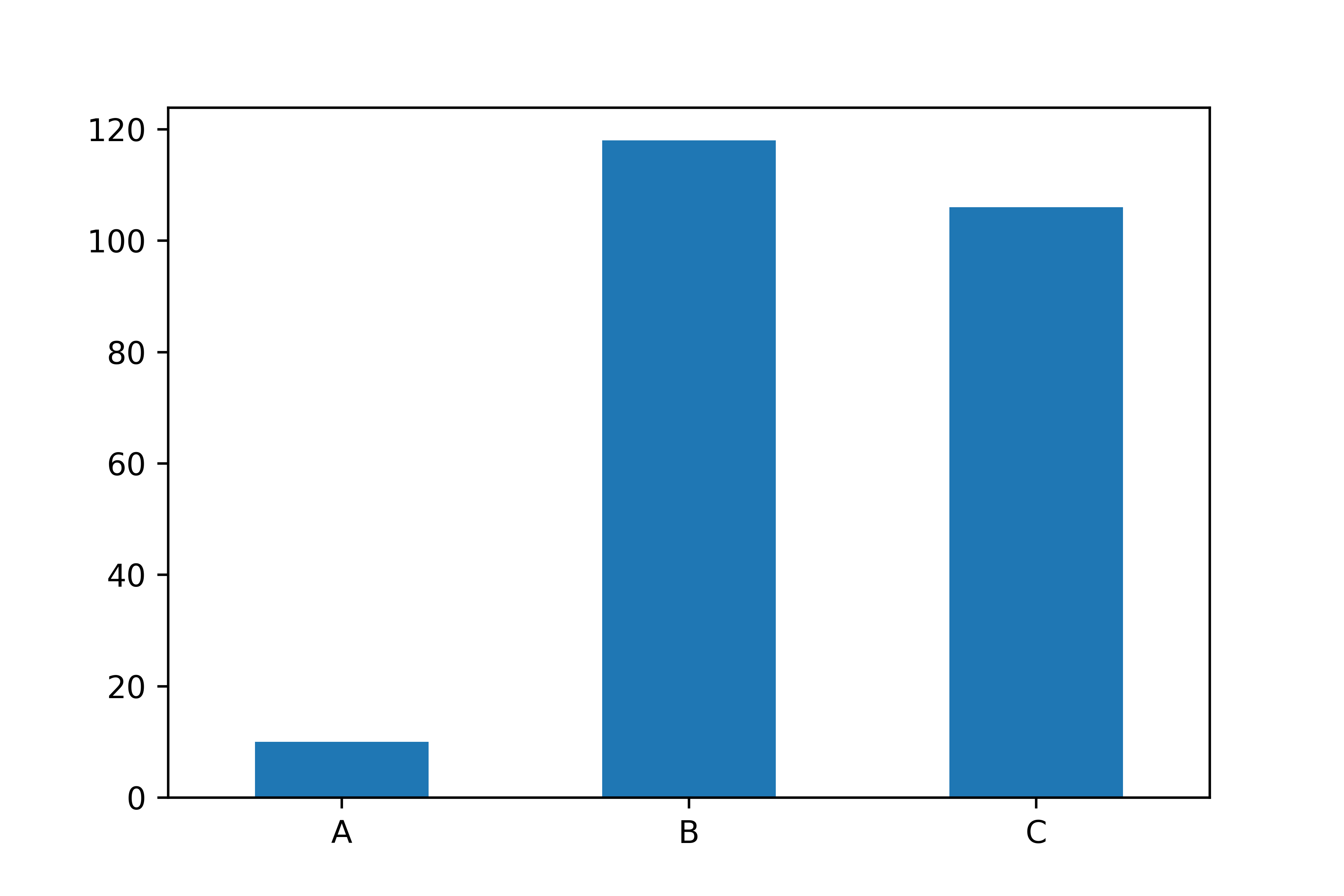
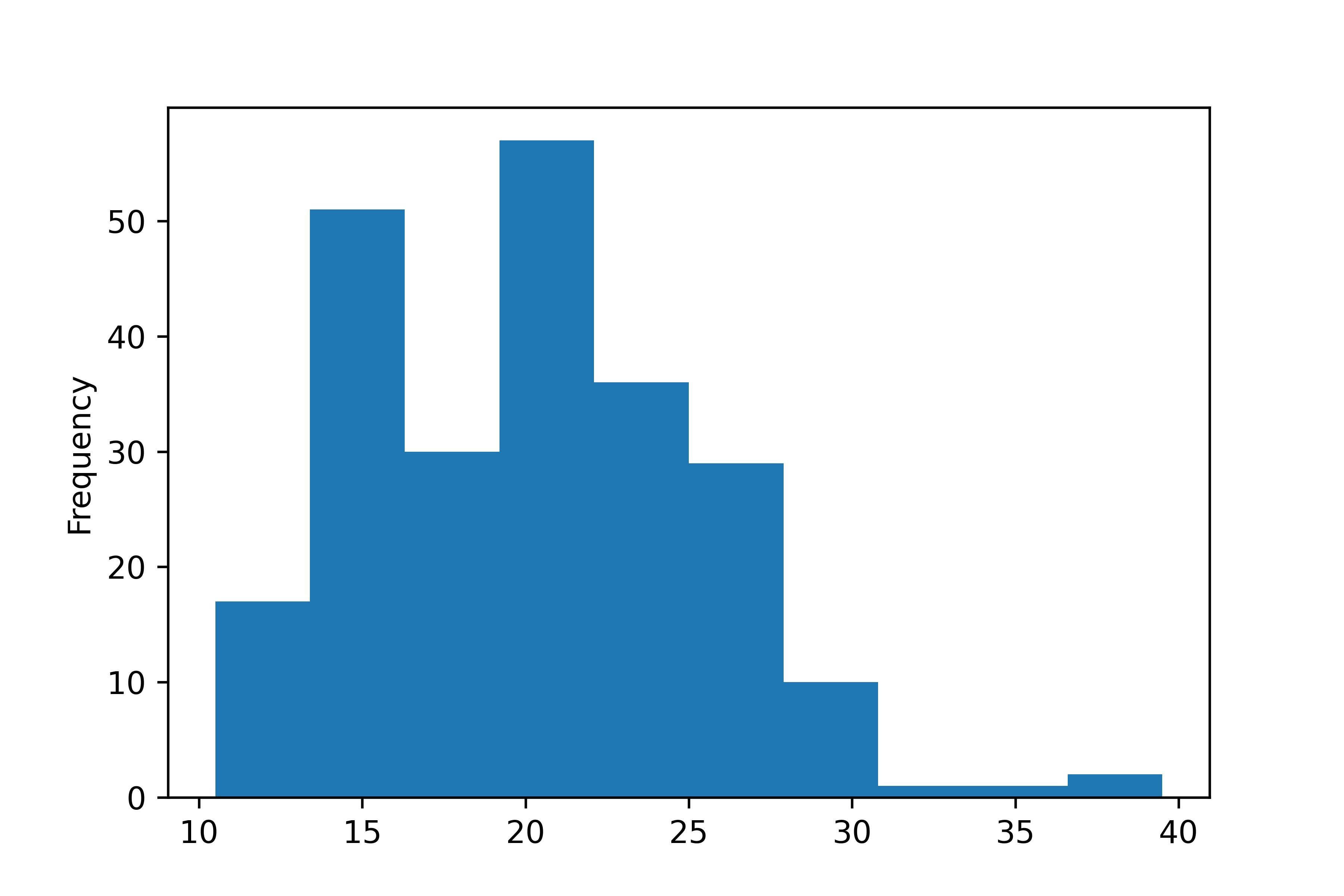
문제 3. total, asian 변수를 이용해 ‘전체 인구 대비 아시아 인구 백분율’ 파생변수를 추가하고,
히스토그램을 만들어 분포를 살펴보세요.
# 백분율 변수 추가
midwest['ratio'] = midwest['asian'] / midwest['total'] * 100
# 히스토그램 만들기
midwest['ratio'].plot.hist()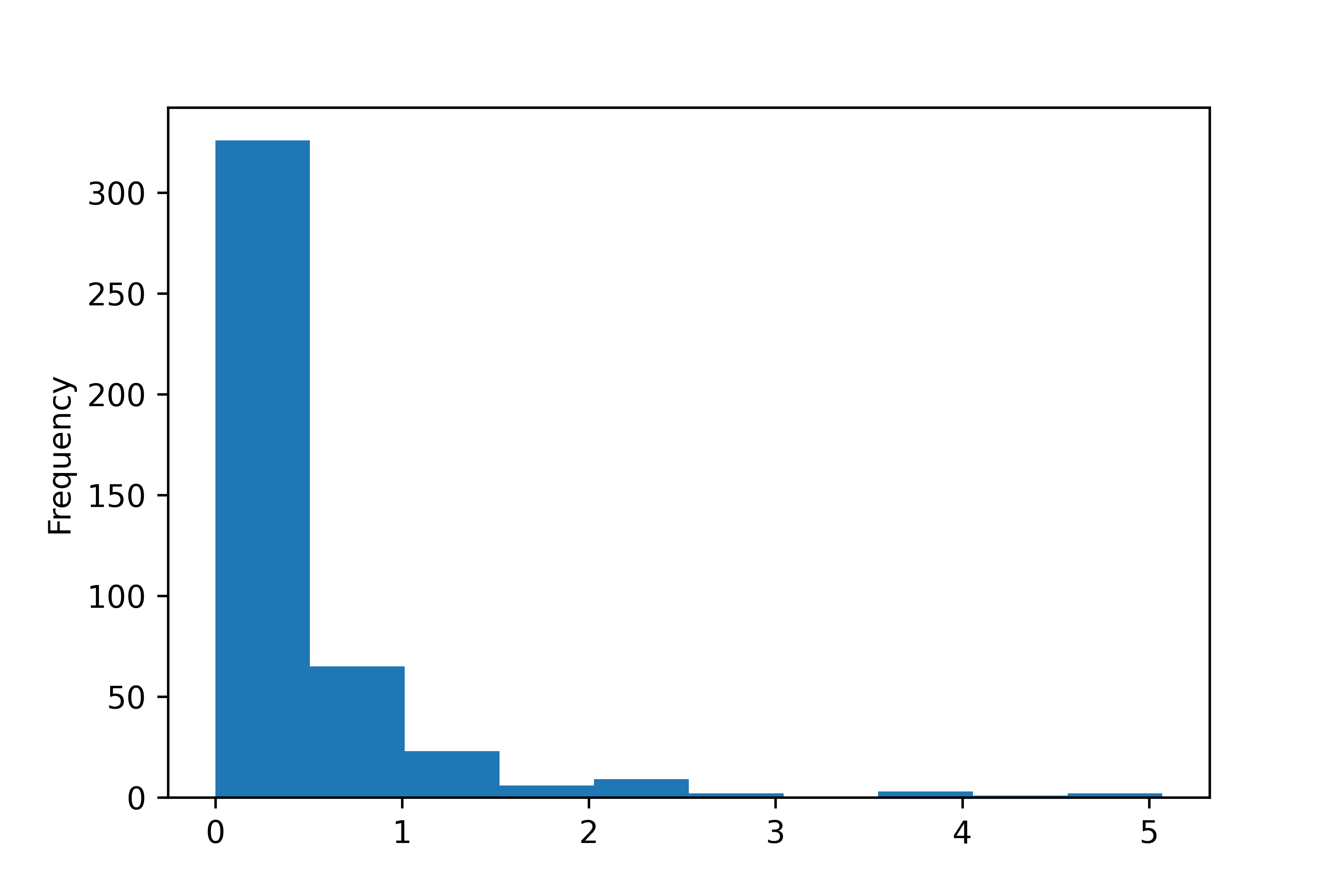
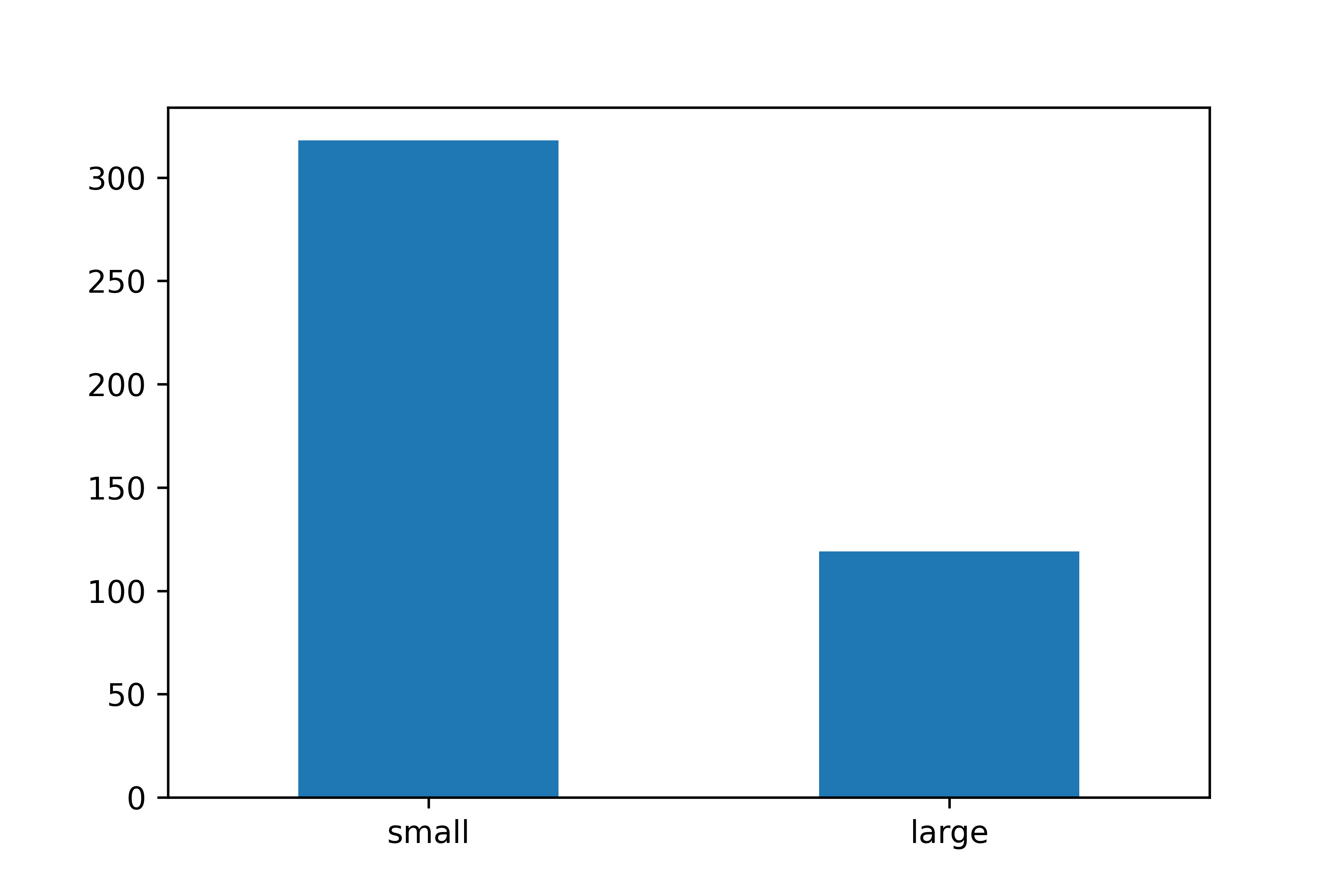
문제 5. 'large'와 'small'에 해당하는 지역이 얼마나 많은지 빈도표와 빈도 막대 그래프를
만들어 확인해 보세요.
# 막대 그래프 만들기
count_group.plot.bar(rot = 0)