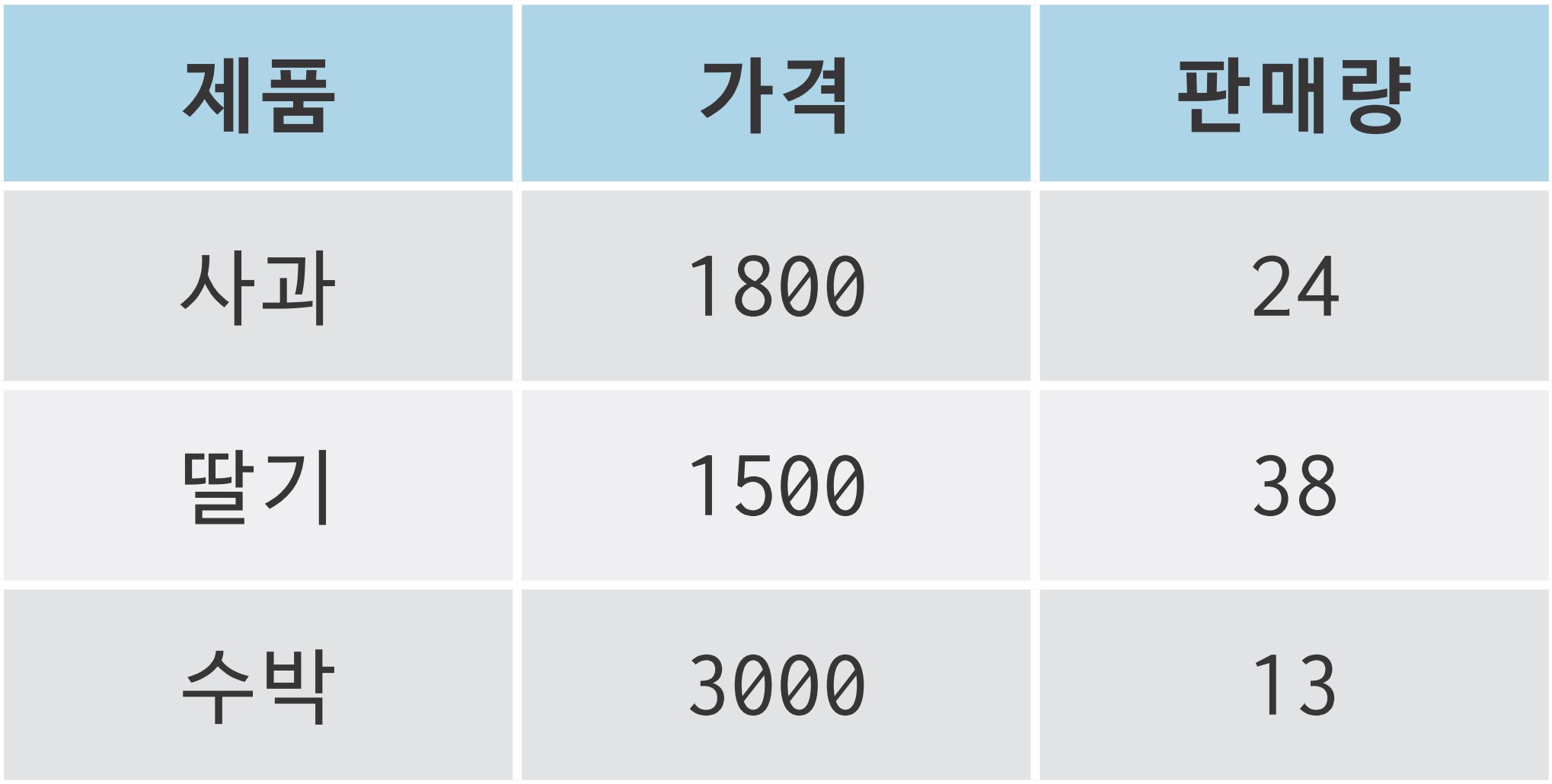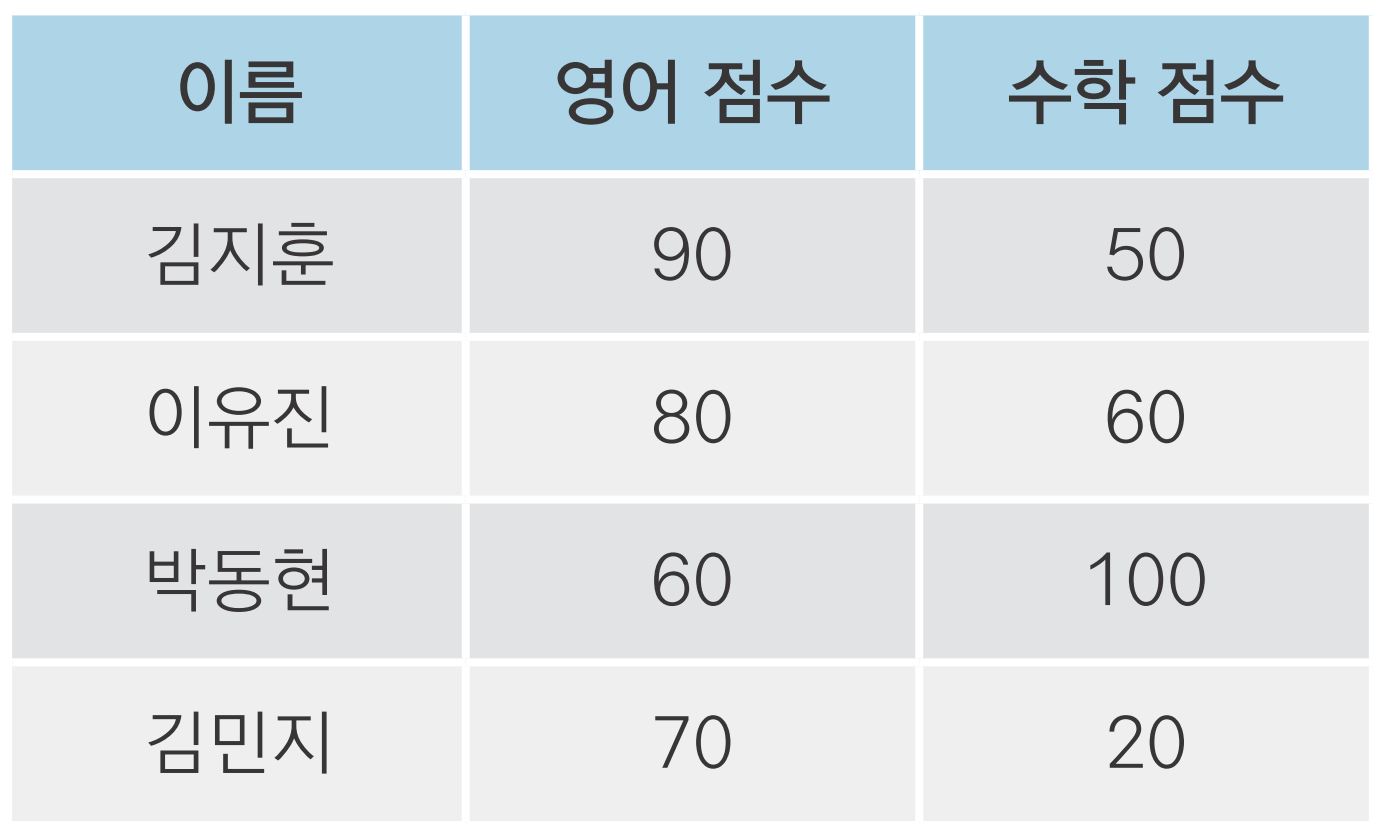
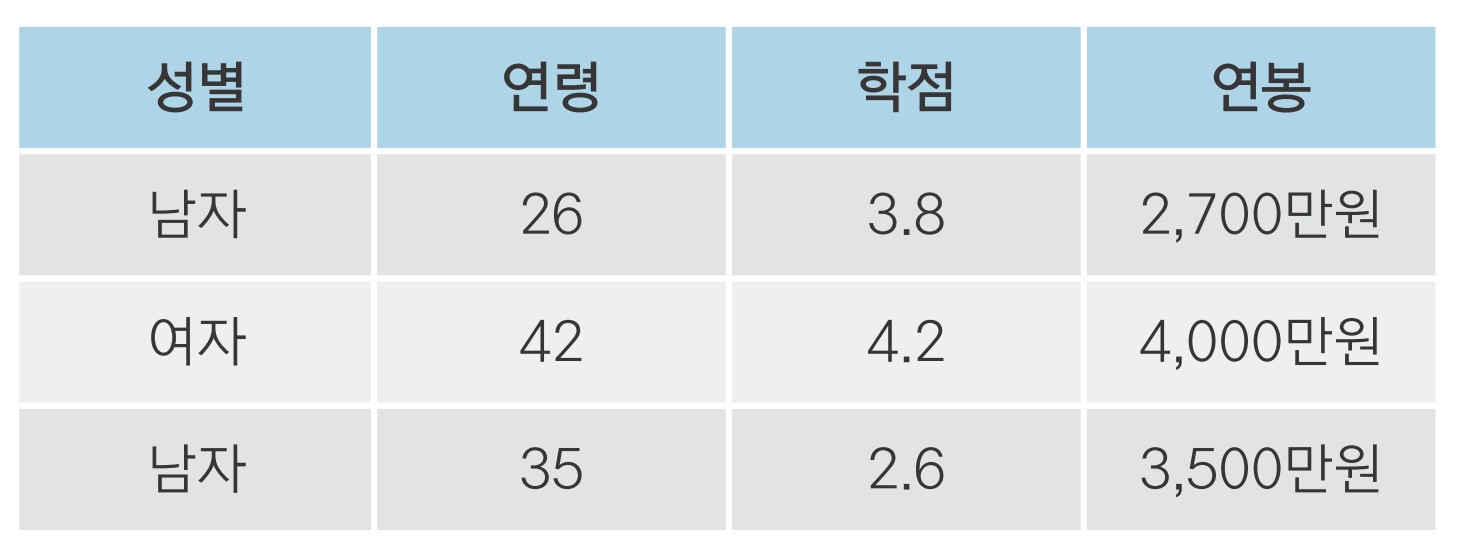
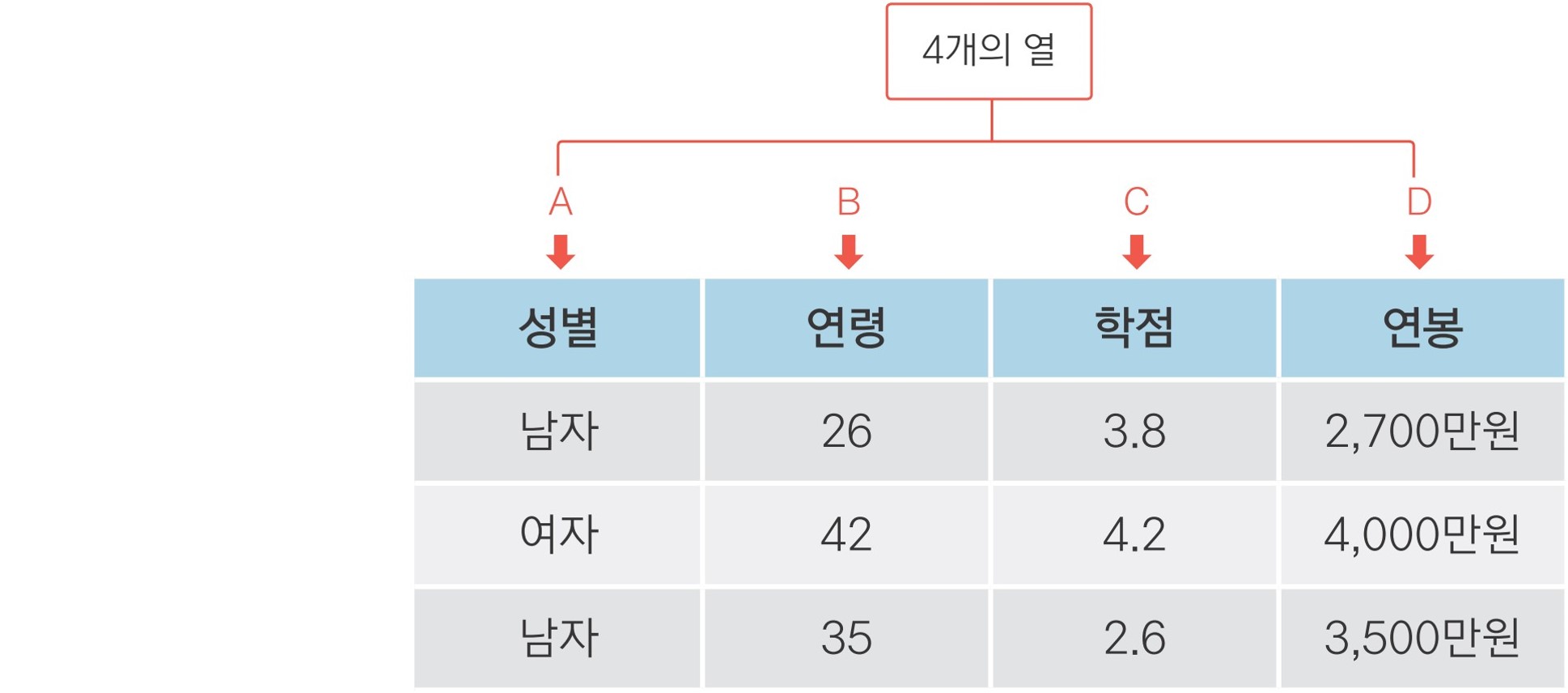
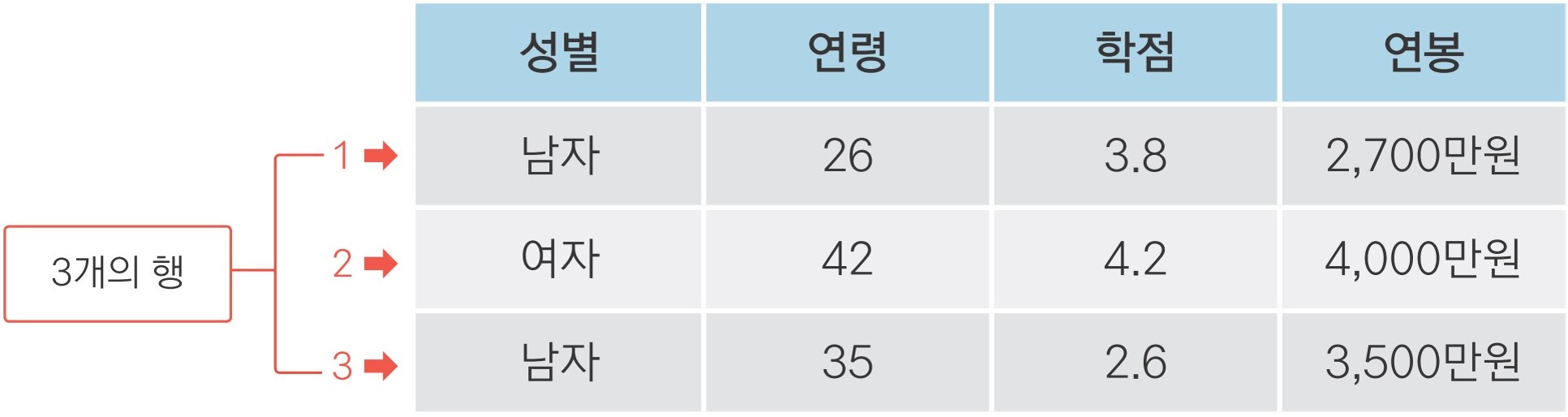
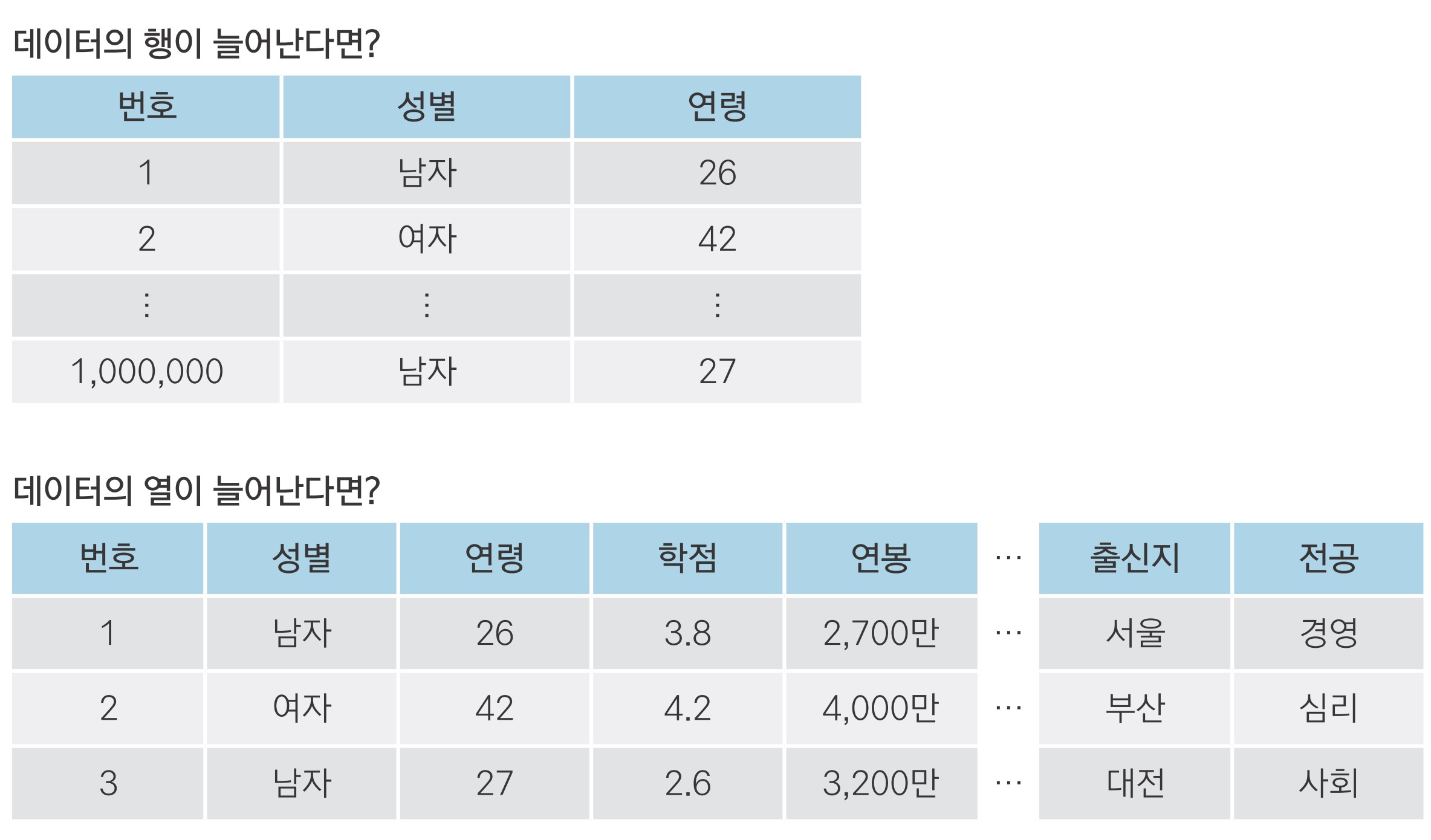
import pandas as pd
df = pd.DataFrame({'name' : ['김지훈', '이유진', '박동현', '김민지'],
'english' : [90, 80, 60, 70],
'math' : [50, 60, 100, 20]})
df name english math
0 김지훈 90 50
1 이유진 80 60
2 박동현 60 100
3 김민지 70 20